O novo sistema operacional da Microsoft para cloud computing, Windows Azure, começa a chegar ao mercado na segunda metade de 2009, e os preços serão definidos por um conjunto de métricas informou a Microsoft na quinta-feira (30/10).
No site do Azure, a empresa explica que o novo sistema será oferecido diretamente pelo Microsoft Online Customer Portal e por meio de fornecedores de software independentes se o usuário adquirir uma aplicação ISV que use a plataforma Azure Services.
A Microsoft reitera que o Azure será oferecido gratuitamente durante o período chamado Community Technology Preview, mas uma vez lançado comercialmente, o sistema torna-se pago e será cobrado de acordo com o volume de recursos consumido pelo cliente. A Microsoft pretende dividir o consumo baseado em plataformas de serviços e em usos específicos.
O tempo de consumo de CPU será medido em horas, a banda ou o acesso ao data center da Microsoft será verificado por Gigabytes, assim como é feito em uso de armazenamento de dados; e transações serão medidas por solicitações.
As métricas para uso da plataforma online serão divididas em seções. O Windows Azure será cobrado com base em serviços de computação e armazenamento; serviços .Net em controle de acesso e workflow; SQL Services em bancos de dados serão cobrados por aplicações de cada linha de negócios; e o SharePoint, que não está incluso na versão inicial do Azure, será cobrado com base em componentes usados pelos desenvolvedores e embutivos em suas aplicações.
Além disso, a Dell anunciou que lançará um hardware exclusivo - uma versão de seu equipamento para data center com rack - para rodar o Azure
sexta-feira, 31 de outubro de 2008
quarta-feira, 22 de outubro de 2008
Computação nas Nuvens (já começou)
A operadora T-Mobile, em conjunto com o Google, lançaram oficialmente hoje nas lojas dos EUA o G1, o primeiro smartphone com o sistema operacional móvel Android.
Reservado por 1,5 milhões de pessoas (não confirmado), o aparelho promete revolucionar a forma como se interage com a web no mundo mobile, além de tirar proveito máximo da computação em nuvem.
E você, está pronto para experimentar essa revolução?
Reservado por 1,5 milhões de pessoas (não confirmado), o aparelho promete revolucionar a forma como se interage com a web no mundo mobile, além de tirar proveito máximo da computação em nuvem.
E você, está pronto para experimentar essa revolução?
sexta-feira, 17 de outubro de 2008
quarta-feira, 15 de outubro de 2008
terça-feira, 14 de outubro de 2008
Entendedno a Expressão Cloud Computing
Cloud computing é a expressão do momento em tecnologia. Nomes de peso como Amazon, AT&T, Dell, HP,IBM, Intel, Microsoft e Yahoo já anunciaram planos e investimentos na área e o Gartner acaba de liberar um relatório que aponta o cloud computing como uma das três mais importantes tendências emergentes nos próximo três a cinco anos.
Mas se há um consenso de que esta é a hora do cloud computing, não é possível dizer que haja uma idéia definida comum do que realmente é a chamada computação em nuvem. As opiniões são variadas e um bom exemplo de que o conceito ainda está nublado é o divertido vídeo da fornecedora Joyent, que mostra personalidades notórias como o visionário da web 2.0, Tim O'Reilly, o editor-chefe da CNet, Dan Farber, e o co-fundador do Wodpress, Matt Mullenweg, dando visões bastante distintas sobre o tema.
Mas se há um consenso de que esta é a hora do cloud computing, não é possível dizer que haja uma idéia definida comum do que realmente é a chamada computação em nuvem. As opiniões são variadas e um bom exemplo de que o conceito ainda está nublado é o divertido vídeo da fornecedora Joyent, que mostra personalidades notórias como o visionário da web 2.0, Tim O'Reilly, o editor-chefe da CNet, Dan Farber, e o co-fundador do Wodpress, Matt Mullenweg, dando visões bastante distintas sobre o tema.
segunda-feira, 13 de outubro de 2008
Web Standards Project – WaSP
No início, fabricantes de browsers, W3C e desenvolvedores começaram quase que ao mesmo tempo.
Neste começo não brotaram desenvolvedores web do chão. Essa profissão não existia. Os primeiros que trabalharam nessa área, migraram de profissões parecidas: quem era programador desktop naquele tempo, começou a programar para web. Quem era designer de impresso, começou a fazer design para web.
Os desenvolvedores
Os programadores estavam se acostumando com a maneira nova de criar sistemas e sites para web. E designers estavam se habiatuando às diferenças que existiam no design para web e impresso. Haviam muitas coisas para se acostumar, começando pelos erros de compatibilidade.
O W3C
O W3C foi criado para regulamentar e criar padrões para a publicação de conteúdo na web. Quando ele começou, não haviam documentos completos, com listas e regulamentos explicando cada um dos padrões. Esses documentos eram rascunhos, muitas vezes incompletos e com apenas uma descrição do que seria aquele padrão.
Com a falta de documentação completa e detalhada, os browsers aproveitavam para criar códigos proprietários, dificultando o desenvolvimento.
Os browsers
O Netscape (antigo Mosaic), era o browser com a maior base de usuários. Para ser sincero, não haviam muitos browsers concorrentes naquela época. A Microsoft, aproveitou o poder que ganhara com a distribuição do Windows com a IBM, e criou o Internet Explorer para concorrer com o Netscape. Foi aí que a Guerra dos Browsers começou.
A guerra por usuários somada com a falta de padrões resultou em códigos proprietários. Conquiste os desenvolvedores e conquistará a web.
Todo esse tumulto no começo da web fez com que o desenvolvimento de sites se tornasse mais complicado, confuso. Em conseqüência a mão de obra se tornava mais cara e o custo de desenvolvimento também. Era caro comprar um site e era mais caro ainda manter esse site.
Era preciso fazer duas versões de sites: uma para Internet Explorer e outra para Netscape. Qualquer atualização ou alteração de layout, era necessário modificar as duas versões. Isso significava trabalho em dobro, logo o custo aumentava.
A Cavalaria - WaSP
Um grupo de desenvolvedores, na maioria designers, formaram um movimento chamado Web Standards Project – WaSP. Um grupo cuja missão seria divulgar os Padrões Web como guias para o desenvolvimento web. O projeto era encabeçado por profissionais como Jeffrey Zeldman, inconformados com o caminho que o desenvolvimento web estava caminhando. E eles tinham toda a razão.
A primeira grande coisa que fizeram foi convencer a Netscape a doar para a comunidade o engine do Netscape. Um grande feito que se não fosse alcançado, hoje não teríamos a fundação Mozilla com seu browser Firefox.
A segunda missão foi fazer com que os fabricantes de browsers seguissem as idéias e recomendações do W3C.
O diferencial naquele tempo dos browsers era apenas o número de usuários. Não haviam add-ons, interface interligada com serviços sociais, leitores de feeds, nem nada do gênero. Seguir o W3C era dizer adeus ao código proprietário e abrir oportunidades para os desenvolvedores a criarem sites para o browser concorrente.
Outro objetivo do grupo era fazer com que os desenvolvedores também adotassem os Padrões do W3C. E esse objetivo está sendo cumprido até hoje.
A resitência de hoje, não é nada com a resistência encontrada há 5 anos atrás. Os desenvolvedores estão mais aberto às novas propostas e os novos profissionais já começam aprendendo da maneira correta.
Hoje as coisas estão bem mais fáceis. Browsers e desenvolvedores lutam a favor dos padrões. W3C e entusiastas estudam novos padrões e pedem sugestão dos profissionais.
Com o amadurecimento das partes, o conhecimento se renova e desenvolver para web fica mais divertido
quinta-feira, 9 de outubro de 2008
Indicação de Popularidade das Linguagens de Programação
Segundo o instituto TIOBE, o mais sério do mercado, na avaliação das Liguagens de Programação.
O Ranking de Outubro dar-se da seguinte forma:
ATENÇÃO: O índice TIOBE não é sobre a melhor linguagem de programação, e sim, a línguagem na qual a maioria das linhas de código são escritas no mundo.
O Ranking de Outubro dar-se da seguinte forma:
- Java
- C
- C++
- VisualBasic
- PHP
- Python
- Perl
- C#
- Delphi
- Rubi
ATENÇÃO: O índice TIOBE não é sobre a melhor linguagem de programação, e sim, a línguagem na qual a maioria das linhas de código são escritas no mundo.
quarta-feira, 8 de outubro de 2008
Photoshop nas Nuvens!!!
A não ser que seja um erro de digitação, o serviço gratuito do site Photoshop Express não oferece nenhuma capacidade de edição profissional de imagens. Trata-se, na verdade, de um produto Beta da Adobe que oferece ferramentas intuitivas e eficientes para que iniciantes tenham um gostinho de tudo que o gigante Photoshop tem a oferecer. Além disso, ele ainda oferece 2 GB de armazenamento de imagens online e ferramentas (rudimentares) de compartilhamento dos arquivos.
Os controles de ajuste de cor e brilho, por exemplo, ilustram bem a ênfase na simplicidade que o Express oferece. Clicando na ferramenta de saturação de cor, você verá seis miniaturas da imagem que você está editando com os diferentes resultados que os níveis de saturação vão gerar. Você só tem que escolher o que mais gostar. Simples assim. No geral, porém, o filtro Auto Correct deve fazer tudo aquilo que você precisa para uma edição rápida de uma foto que você vai mandar para o Picasa, o Facebook ou o Photobucket.
Algumas funcionalidades que outros sites similares oferecem, no entanto, não são oferecidas pelo Photoshop Express. É o caso da impressão de imagens e da criação de álbuns, ainda que você possa adicionar informações sobre cada imagem tratada. Mas não é possível associar fotos a pessoas, lugares ou eventos, além de o sistema não permitir que se deixe comentários sobre as fotos, como fazem o Flickr e o Picasa. Além desses inconvenientes, o processo de upload das imagens é desajeitado e restritivo.
Do modo como está configurado, o site se encaixa melhor às necessidades de um usuário do Facebook, por exemplo, que não precisa da monstruosa capacidade de edição do Photoshop tradicional. Mas o Express pretende ser apenas um editor de imagens casual e, para o que se propõe, o site é bem implementado e envolvente.
Os controles de ajuste de cor e brilho, por exemplo, ilustram bem a ênfase na simplicidade que o Express oferece. Clicando na ferramenta de saturação de cor, você verá seis miniaturas da imagem que você está editando com os diferentes resultados que os níveis de saturação vão gerar. Você só tem que escolher o que mais gostar. Simples assim. No geral, porém, o filtro Auto Correct deve fazer tudo aquilo que você precisa para uma edição rápida de uma foto que você vai mandar para o Picasa, o Facebook ou o Photobucket.
Algumas funcionalidades que outros sites similares oferecem, no entanto, não são oferecidas pelo Photoshop Express. É o caso da impressão de imagens e da criação de álbuns, ainda que você possa adicionar informações sobre cada imagem tratada. Mas não é possível associar fotos a pessoas, lugares ou eventos, além de o sistema não permitir que se deixe comentários sobre as fotos, como fazem o Flickr e o Picasa. Além desses inconvenientes, o processo de upload das imagens é desajeitado e restritivo.
Do modo como está configurado, o site se encaixa melhor às necessidades de um usuário do Facebook, por exemplo, que não precisa da monstruosa capacidade de edição do Photoshop tradicional. Mas o Express pretende ser apenas um editor de imagens casual e, para o que se propõe, o site é bem implementado e envolvente.
Firefox Mobile alpha nas próximas semanas!
O navegador móvel da Mozilla, que está atualmente em desenvolvimento e possui o codenome Fennec, deverá ganhar uma versão alpha dentro de algumas semanas.
John Lilly, Chefe-Executivo da Mozilla, afirmou que o desenvolvimento do produto está progredindo rapidamente.
"Queremos ter certeza que a internet no celular será como a Web que conhecemos, ao contrário daquilo que a indústria móvel oferece hoje, que está fechada, com redes separadas e experiência de uso danificada para o usuário. A primeira coisa a fazer é trazer o Firefox para aparelhos móveis. Estamos trabalhando nisso, e nós vamos ver alguns alphas dentro de algumas semanas. " disse Lilly em entrevista ao San Jose Mercury News:
Embora as primeiras versões do Fennec já estejam sendo testadas em aparelhos da Nokia, a Mozilla possui planos e intenção de trazer suporte multi-plataforma ao navegador.
sábado, 4 de outubro de 2008
Microsoft dá novo ultimato ao Windows XP
Microsoft vai por fim aos contratos de downgrade que permitem aos integradores vender Windows XP.
O Windows XP não é mais vendido no varejo pela Microsoft para desktops e notebooks desde 30 de junho deste ano. As exceções ficam para os laptops educacionais e netbooks que não possuem configuração suficiente para rodar o Vista.
Apesar disso, quem compra PCs com licenças do Vista Ultimate e Vista Business pode fazer um downgrade para Windows XP. Na prática, esta regra permite que muitos integradores continuem oferecendo a opção de comprar um PC com XP instalado.
A Microsoft vai acabar com esse recurso a partir de 2009. A proibição de downgrade para XP começa a valer em janeiro. Mas a Microsoft dará seis meses para que a indústria se adéqüe à regra, o que na prática estende o ultimato ao XP até junho do ano que vem.
quinta-feira, 2 de outubro de 2008
MS faz qualquer negócio para frear Google
Num sinal de como a Microsoft está desesperada em atrair os usuários de internet norte-americanos para seu site de busca Live Search e afastá-lo do rival Google, a empresa está oferecendo milhas para seus mais freqüentes usuários – mas apenas aqueles que fazem a busca usando o Internet Explorer. Usuários do Firefox, Chrome ou Safari estão fora da promoção.
Flyers com as milhas são das companhias aéreas American Airlines, Delta e US Airways e estão apenas entre algumas das gratificações oferecidas no programa chamado SearchPerks. A estratégia amplia plano da Microsoft de oferecer descontos em dinheiros a quem usar o Live Search para buscar produtos. A companhia precisa atrair os olhares para o Live Search, pois a empresa continua perdendo participação no mercado para o Google.
Microsoft investe nas nuvens com o novo SO "Windows Cloud"
Steve Ballmer, CEO da Microsoft, anunciou que dentro de um mês a MS irá disponibilizar um novo sistema operacional chamado provisoriamente de "Windows Cloud" para desenvolvedores de aplicativos web que trabalham diretamente com o conceito de "computação em nuvem", como por exemplo a suite Zoho.
"O sistema operacional, o que provavelmente terá um nome diferente, é destinado para programadores especializados em aplicações 'cloud-computing', disse Ballmer, em uma conferência de TI promovida pela Microsoft, em Londres" reporta a Computerworld.
O sistema operacional Windows Cloud será um projeto separado a partir da próxima versão do Windows (conhecido atualmente como 7). Seria esta a primeira reação da Microsoft em querer atrapalhar os planos do Google? Certamente, e isso é apenas o começo.
quarta-feira, 1 de outubro de 2008
Netapplications de Setembro!!!
A estatística dos browsers da Netapplications em setembro aponta o Chrome em 4º lugar, desbancando o Opera.
E como já era de se esperar o Internet Explorer continua caindo.
Internet Explorer: 71,52%
Firefox: 19,46
Safari: 6,65%
Chrome: 0,78%
Opera: 0,69%
Netscape: 0,63%
Outros: 0,24%
E como já era de se esperar o Internet Explorer continua caindo.
Internet Explorer: 71,52%
Firefox: 19,46
Safari: 6,65%
Chrome: 0,78%
Opera: 0,69%
Netscape: 0,63%
Outros: 0,24%
terça-feira, 30 de setembro de 2008
segunda-feira, 29 de setembro de 2008
Sun monta equipe para MySQL no Brasil
A Sun Microsystems adquiriu a MySQL no início do ano por 1 bilhão de dólares. Cerca de 400 funcionários da companhia de banco de dados foram absorvidos pela empresa liderada por Jonathan Schwartz. Kaj Arnö, vice-presidente de relações com a comunidade MySQL, afirma que o maior interesse da Sun na compra do MySQL AB é aumentar a receita com a venda de hardware, por meio de sua linha de servidores de banco de dados.
Outra estratégia é transformar usuários da versão gratuita do MySQL em clientes corporativos da Sun. O MySQL Enterprise reúne alguns programas proprietários para monitoração do sistema, além de suporte técnico em diferentes níveis. A mesma linha é adotada com o Solaris, sistema operacional da companhia. A empresa oferece a versão gratuita do OS, a Open Solaris, ao mesmo tempo em que vende o software com serviços agregados a seus clientes corporativos.
“O MySQL está instalado em mais de 10 milhões de máquinas globalmente. Com a aquisição, a Sun quer competir num mercado estimado em 17 bilhões de dólares”, afirma Arnö.
Por enquanto, a equipe brasileira será pequena, formada por três profissionais na área de vendas, dois para suporte e dois paras consultoria de pós-venda. “O MySQL será tratado como mais uma linha de negócios dentro da Sun”, afirma Rodolfo Fontoura, presidente da Sun no Brasil.
Segundo Fontoura, a Sun trabalhará por meio de canais de vendas, com foco inicial no segmento corporativo. Há muitos usuários de MySQL que mantêm o banco de dados sob a custódia de equipes internas de TI. Mas, apesar do MySQL estar disponível a qualquer um, Fontoura lembra que, dependendo da complexidade das aplicações desenvolvidas em cima dele, é arriscado não contar com um suporte técnico mais qualificado.
“O nosso desafio, agora, é capacitar os canais de venda e incentivar o treinamento de profissionais dedicados a MySQL”, diz o executivo.
domingo, 28 de setembro de 2008

JQuery mudou minha vida!
Olá pessoal, após uma breve estiada. estou voltando com o blog Mandamentos Web.
espero deixar aqui um acervo rico da evolução no desenvolvimento web.
Quero apresentar a vocês o jquery, um cara que mudou minha vida, (hehehe) sem exageros.
alem de plugins de muito fácil utilização e implantação. vou dar uma pequena introdução aos novos intusiastas.
Vejam vocês mesmos com 2 plugins ki estám virando moda.
e
Bom proveito!!!
domingo, 18 de maio de 2008
XHTML-Print 1.0
XHTML Print é uma recomendação formal do W3C que é desenvolvido para a impressão, desde dispositivos móveis a impressoras simples, e é baseado no XHTML Basic.
O objetivo do XHTML Print é promover um formato de descrição de página onde o conteúdo e a reprodução do mesmo sejam prioritários frente a descrições de página como o PostScript, onde o controle do layout também forma parte do objetivo da descrição.
XHTML Print herda a estrutura e a codificação especificados no XHTML.
saiba mais em: http://www.w3.org/TR/2006/REC-xhtml-print-20060920/
quarta-feira, 14 de maio de 2008
Google será mais lucrativo que Windows até 2009
No início de 2009 o monopólio do Google deve superar o maior monopólio da história da informática: O Microsoft Windows! Estudos provam que somente o buscador do Google (aqui não se incluem os outros serviços das empresa) deve superar o histórico monopólio do Windows, como negócio mais rentável da história.
Os gráficos abaixo mostram a lucratividade por trimestre do Google e do Windows no período de Setembro de 2006 a Março de 2008 e prevêem que no início de 2009 o Google deve lucrar mais que o Sistema Operacional Windows.

A preocupação da Microsoft diminui quando colocamos em jogo o Microsoft Office, fonte de muita lucratividade para a Microsoft e que deve manter bons rendimento à empresa pelos próximos anos.
Se compararmos o Google ao Live, buscador da Microsoft, a lucratividade do Google torna-se esmagadora, como pode-se constatar no gráfico abaixo:

Os gráficos abaixo mostram a lucratividade por trimestre do Google e do Windows no período de Setembro de 2006 a Março de 2008 e prevêem que no início de 2009 o Google deve lucrar mais que o Sistema Operacional Windows.
A preocupação da Microsoft diminui quando colocamos em jogo o Microsoft Office, fonte de muita lucratividade para a Microsoft e que deve manter bons rendimento à empresa pelos próximos anos.
Se compararmos o Google ao Live, buscador da Microsoft, a lucratividade do Google torna-se esmagadora, como pode-se constatar no gráfico abaixo:
segunda-feira, 12 de maio de 2008
Google Maps exibe Construções 3D

Estava utilizando o Google Maps agora pouco para testar algumas features sobre reviews de lugares e me deparei com uma situação um tanto quanto estranha:
O Google Maps está exibindo a forma da construção. Isso mesmo! Por padrão os prédios e casas estão com os seus contornos 3D. Pelo que eu sei, isto era apenas possível no Google Earth.
domingo, 11 de maio de 2008
Windows Live Messenger bloqueia www.youtube.com
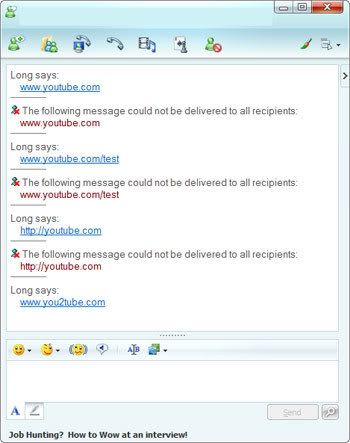
De acordo com informações do site istartedsomething.com, alguns usuários do Windows Live Messenger estão atualmente impossibilitados de enviar links do YouTube para os seus contatos.
Como é possível visualizar na imagem abaixo, as mensagens que contêm texto ou links para “www.youtube.com” deixam de ser entregues e exibem uma informação de erro.
Seria muito fácil afirmar que a Microsoft com “inveja” poderia estar realizando uma censura ao portal de vídeos do Google, mas esperamos positivamente que neste caso seja um problema no sistema do produto.
quarta-feira, 7 de maio de 2008
sábado, 3 de maio de 2008
30 anos de spam e pouco a comemorar
No dia 3 de maio de 1978, a primeira mensagem comercial indesejada surgiu na Arpanet - rede das Forças Armadas dos EUA e embrião daquilo que hoje é a Internet.
A mensagem foi escrita dois dias antes e enviada para 393 felizardos na rede do Departamento de Defesa norte-americano. Depois disso, o fenômeno se espalhou para a Usenet e para os links nas páginas da Web.
O termo spam é uma referência à um quadro dos humoristas ingleses do Monthy Pyton, onde todas as refeições vinham com carne enlatada (spam, em inglês) sem que o prato tivesse sido pedido pelo freguês.
Em 2004, Bill Gates disse que o spam seria erradicado em dois anos e apresentou um plano da Microsoft para resolver o problema. O esquema incluia um sistema de perguntas para autenticar a mensagem. Até a idéia de um "selo de correio" digital foi aventada para impedir o recebimento de spams.
Mas, da mesma forma que os sistemas de defesa evoluiram, os métodos de spam também ganharam sofisticação. Hoje, o alvo das mesnagens indesejadas e dos criadores de vírus são os celulares e outros dispositivos móveis.
Cerca de 80% dos usuários de celular mundo afora já receberam mensagens indesejadas e de todas as mensagens de email, 95% são spam. A tática não seria viável caso não houvesse resposta à essas mensagens. Mas elas existem: 11% dos usuários já comprou algum produto conhecido por meio de spam.
A mensagem foi escrita dois dias antes e enviada para 393 felizardos na rede do Departamento de Defesa norte-americano. Depois disso, o fenômeno se espalhou para a Usenet e para os links nas páginas da Web.
O termo spam é uma referência à um quadro dos humoristas ingleses do Monthy Pyton, onde todas as refeições vinham com carne enlatada (spam, em inglês) sem que o prato tivesse sido pedido pelo freguês.
Em 2004, Bill Gates disse que o spam seria erradicado em dois anos e apresentou um plano da Microsoft para resolver o problema. O esquema incluia um sistema de perguntas para autenticar a mensagem. Até a idéia de um "selo de correio" digital foi aventada para impedir o recebimento de spams.
Mas, da mesma forma que os sistemas de defesa evoluiram, os métodos de spam também ganharam sofisticação. Hoje, o alvo das mesnagens indesejadas e dos criadores de vírus são os celulares e outros dispositivos móveis.
Cerca de 80% dos usuários de celular mundo afora já receberam mensagens indesejadas e de todas as mensagens de email, 95% são spam. A tática não seria viável caso não houvesse resposta à essas mensagens. Mas elas existem: 11% dos usuários já comprou algum produto conhecido por meio de spam.
terça-feira, 29 de abril de 2008
Google desenvolve nova geração de busca por imagem
Dois cientistas do Google apresentaram na semana passada um documento na Conferência World Wide Web em Pequim na qual expõe uma nova visão no futuro da pesquisa de imagens.
Notavelmente, a nova tecnologia de pesquisa de imagem não se baseia no texto associada a imagem para determina-la. Google poderá usar seus computadores para analisar fotos, e associá-las de forma a torna-las ordenada através de buscas com palavra-chave. Será algo semelhante ao atual PageRank, mas sem analise de links.
Os Googlers Yushi Jing e Shumeet Baluja argumentam que o Google está pronto para ver para além do texto. No documento divulgado, eles descrevem seus esforços para aplicar o estado da arte imagem em software de reconhecimento, o que possibilitará descobrir o que as imagens se referem.
A nova geração deve observar as características visuais de imagens populares e, em seguida, determinar a classificação baseada em semelhanças entre as imagens.

Notavelmente, a nova tecnologia de pesquisa de imagem não se baseia no texto associada a imagem para determina-la. Google poderá usar seus computadores para analisar fotos, e associá-las de forma a torna-las ordenada através de buscas com palavra-chave. Será algo semelhante ao atual PageRank, mas sem analise de links.
Os Googlers Yushi Jing e Shumeet Baluja argumentam que o Google está pronto para ver para além do texto. No documento divulgado, eles descrevem seus esforços para aplicar o estado da arte imagem em software de reconhecimento, o que possibilitará descobrir o que as imagens se referem.
A nova geração deve observar as características visuais de imagens populares e, em seguida, determinar a classificação baseada em semelhanças entre as imagens.
sexta-feira, 25 de abril de 2008
Fazendo do Jeito Certo
A maior parte dos desenvolvedores web, designers ou programadores, começaram antes do surgimento dos movimentos em prol dos padrões web, usando tabelas para montar layouts em editores WYSIWYG, e ainda hoje este método é usado na maioria dos projetos de internet. Logo, é natural que muita gente, ao começar a entender o valor dos padrões, se pergunte como migrar do desenvolvimento “tradicional” para o desenvolvimento de código semanticamente coerente.
É um caminho muito duro o que separa o desenvolvedor acostumado a editores visuais do desenvolvimento de código coerente. E é muito comum que o designer desista após uma primeira tentativa frustrada de desenvolver um website tableless, com layout CSS e XHTML validado.
Por isso gostaria de propor um caminho gradual, mais suave, para aqueles que querem se aventurar pela primeira vez pelos padrões web. O princípio desse método é da recompensa. Você pode obter um grande benefício aproximando seu código dos padrões web, mesmo que não faça tudo de uma vez. Quero mostrar como você pode começar, e obter benefícios imediatos.
Limpe seu HTML
A minha primeira recomendação é que você estude CSS. Comece pela formatação básica de fonte, cor e tamanho. Isso vai te garantir código menor e produtividade maior com pouquíssimo esforço.
Assim, ao criar um item de menu, você vai evitar códigos como este:
<a href="parceiros.asp"><font
face="Arial, Helvetica, Sans-serif" size="2"
color="#FF3300"><b>Parceiros</b></font></a>
Colocando no lugar:
<a href="parceiros.asp" class="menu">Parceiros</a>
Tendo no CSS:
.menu{
font-family: Arial, Helvetica, Sans-serif;
font-size: 80%;
font-weight: bold;
color:#FF3300;
}
Como você pode ver, o CSS é extremamente simples. Aprender esses quatro atributos, mais o “font-style” (para fazer itálico), é a primeira coisa que eu recomendo. É claro, isso apenas faz cócegas nas possibilidades do CSS, ainda há muito o que aprender, mas recomendo começar por aí porque é algo que você pode aprender em alguns minutos e vai te salvar muito, muito tempo. E você vai começar a ter o controle da formatação, tendo todas as definições de fonte em um único arquivo, podendo alterar, por exemplo, a qualquer momento, a fonte de todo o conteúdo ou de todos os menus do site.
O passo seguinte para limpar seu HTML é se livrar do spacer.gif, aquele gif transparente de 1 pixel que se usa para dar espaços em tabelas, e das dezenas de tabelas aninhadas. Para isso vamos começar a estudar o “box-model”.
O pulo-do-gato aqui é um atributo CSS chamado padding. O padding é a distância entre as bordas de um elemento e o texto dentro dele. Assim, se é preciso que o conteúdo de uma célula esteja a 10 pixels da borda esquerda, ao invés de inserir uma célula extra como espaçador, ou inserir mais uma tabela, basta definir uma classe para essa célula. Uma vez que você já está colocando a formatação no CSS, provavelmente esta célula já tem uma classe. Então basta:
.conteudo{
padding-left:10px;
}
Isso vai fazer com que o texto esteja a 10 pixels da borda esquerda do documento. Ah, claro, o CSS também pode livrar você de definir no HTML as bordas e o background das células de sua tabela. Lembre-se, quanto mais layout e formatação você colocar no CSS, mais controle terá sobre seu site, principalmente em mudanças de layout durante o processo de produção e em futuras manutenções. O site também será mais leve para carregar.
Concluímos então que, após aprender os atributos de formatação de fonte, o passo seguinte é aprender os atributos background, border e padding. Indo até aqui você com certeza será um desenvolvedor muito mais feliz! Depois de limpar seu HTML, ganhar controle sobre a formatação de seu site e se tornar muito mais produtivo, você está pronto para passar à segunda etapa, correndo atrás da semântica.
Começando o Trabalho de Gente Grande
Muito bem, agora você já pode limpar seu código. Vamos estudar um exemplo prático. No começo de cada uma de suas páginas você tem um título, cujo código hoje é assim:
<font face="Arial, Helvetica, Sans-serif" size="4"
color="#FFFF00"><b>Novidades</b></font>
Ao limpar esse código, você vai substituir esse monte de tags por uma só. Que tag você vai usar? Como o CSS te permite formatar qualquer elemento, muita gente que começa a estudar o assunto acha que é indiferente que tag usar, e coloca algo como:
<p class="titulo">Novidades</p>
Agora, veja bem, outro desenvolvedor poderia resolver o mesmo problema com:
<div class="titulo">Novidades</div>
E o resultado visual poderia ser o mesmo. Acontece que há algo na natureza do HTML que nos diz que tag usar. Chamamos esse algo de “semântica”: as tags do HTML tem significado. A tag P é para parágrafos, a tag DIV para divisões no conteúdo, e há uma série de tags para título, h1, h2, h3, h4, h5 e h6. Assim, se você pode usar qualquer tag, pode fazer assim:
<h1>Novidades</h1>
O que você ganha com essa preocupação? Os buscadores inteligentes podem ler semanticamente o conteúdo de um documento, entendendo que trecho de código é um título, por exemplo. Assim, escrever HTML semanticamente correto pode melhorar muito sua visibilidade em buscadores. O segundo bom motivo é que você vai saber para que serve cada tag se tiver que mexer nesse mesmo documento daqui a alguns meses. E vai ser mais fácil também se outra pessoa tiver que dar manutenção no seu código.
Logo, use as tags do HTML para aquilo para o que foram criadas:
- dd, dl e dt para listas de definições (um glossário, por exemplo)
- h1 a h6 para títulos
- p para parágrafos
- abbr para abreviaturas e acronym para acrônimos
- blockquote e q para citações longas e curtas
- address para endereços (sabe aquele rodapé onde vai o endereço e o telefone da empresa?)
- ul e ol para listas e li para os itens da lista
Você pode obter uma lista mais abrangente em:
http://www.w3schools.com/xhtml/xhtml_reference.asp
E formate tudo ao seu gosto com CSS.
Finalmente, Livrando-se das Tabelas
Não há bons motivos para você eliminar a qualquer custo todas as tabelas de seu primeiro trabalho. Conheço alguns excelentes profissionais, muito talentosos, que fizeram um ótimo trabalho em sua primeira tentativa de tableless. Mas a maioria dos que eu vi tentarem demoraram muito para conseguir da primeira vez, e alguns não obtiveram os resultados que esperavam. Isso tudo serve para que você possa produzir mais rápido e melhor, não o contrário. Então vá com calma. Faça alguns estudos em tableless, comece eliminando parte das tabelas em seus primeiros trabalhos. Por exemplo, remover as células de tabela que formam o menu, trocando por uma lista (com as tags ul e li), é um ótimo desafio para o primeiro projeto.
Ah, e não se esqueça que para dados como uma tabela periódica ou um calendário a solução semanticamente correta é a tabela mesmo. Ou seja, tableless não é ausência de tabelas, é o seu uso apenas onde é semanticamente justificável.
Não vou entrar em detalhes aqui, porque já escrevi bastante sobre como construir um layout no Tutorial Tableless Básico, mas o conselho é ir com calma, sem estresse. Você logo vai estar produzindo tableless mais fácil do que produz sites com tabelas.
XHTML
Há uma coisa que muita gente que está começando me pergunta: o que é e para que serve esse tal de XHTML? É muito mais simples do que parece. Um arquivo XHTML é um arquivo HTML, que pode ser lido por qualquer browser. Não estamos falando de um novo HTML, com novas tags ou coisa assim. Pelo contrário, o XHTML 1 foi feito para funcionar mesmo em navegadores antigos. Mas, ao mesmo tempo, Um arquivo XHTML é também um arquivo XML válido, que pode ser lido por qualquer interpretador de XML.
Meu primeiro conselho, nesse caso, é que você, se não trabalha com XML, deixe preocupação com o XHTML para depois de dominar bem o código semântico e o layout tableless. Não porque seja complicado, pelo contrário, transformar bom HTML em XHTML é bem simples, mas simplesmente porque você pode obter benefícios muito significativos, e muito mais rapidamente, aprendendo CSS do que XHTML.
O segundo conselho é que você comece a estudar o assunto. Depois de dominar bem layouts CSS, mergulhe no XML. A maioria dos bancos de dados hoje permite extrair dados diretamente em XML e todas as plataformas de aplicações web trabalham bem com XML. E com a poderosa linguagem XSLT você pode muito facilmente oferecer seus os dados em XHTML para o navegador.
Voando Alto
Estamos falando de muito mais do que criar sites estilosos. Há duas semanas esteve aqui um amigo com um Palm novo, um Zire 71, e um celular com acesso à internet. Isso está se tornando cada vez mais barato e comum. Conheço também uma porção de empresas e instituições, entre elas uma série significativa de TeleCentros e órgãos públicos, que estão adotando Linux como sistema operacional para desktops. O Google hoje é responsável por 90% do tráfego que meu site consegue de buscadores. É o primeiro colocado absoluto entre os buscadores. E conseguiu isso indexando semanticamente o conteúdo real dos sites. Praticamente todas as plataformas web estão oferendo suporte a XML e apostando na idéia de webservices.
Quem segue os padrões web não precisa ter medo do futuro. Não importa que browser vai ser o mais usado daqui a dois anos, que tecnologia vai estar na moda ou de onde as pessoas vão estar usando a internet. Seu site estará lá, leve, acessível, atual e útil.
quarta-feira, 23 de abril de 2008
Principais problemas em consultoria de banco de dados
Olá pessoal. Na coluna desta semana abordarei algumas situações críticas nas quais me deparei durante algumas consultorias de banco de dados.
Infelizmente tenho encontrado vários problemas durante as consultorias nas quais participo. Algumas vezes encontro problemas técnicos, outras vezes problemas de coordenação/gerencialmente e até problemas políticos. Por isso resolvi contar nesta coluna alguns dos principais problemas que já encontrei durante a minha experiência como consultor na área de banco de dados. Já havia entrado neste tópico em uma das minhas colunas anteriores, chamada de Pimp My Database, mas desta vez não descreverei uma situação específica.
A idéia aqui é mostrar quais os principais problemas que eu encontrei, e não fazer uma crítica infundada. Geralmente estes problemas possuem soluções simples, porém é preciso primeiro a conscientização do impacto destes problemas no ambiente como um todo antes de procurar uma solução.
Cursor em trigger
Muitos desenvolvedores estão acostumados a trabalhar com cursores, ou seja, a maneira de se processar os dados de uma tabela linha-a-linha. Esta técnica pode fazer sentido em muitas situações relacionadas à programação, porém em 99% das vezes que ela é utilizada dentro do banco de dados devemos substituí-la. No que diz respeito à banco de dados, os cursores consomem muitos recursos, são ineficientes, geram locks desnecessários e tornam mais difícil a compreensão do código.
Como exemplo do qüão prejudicial isso pode ser eu cito o uso do cursores dentro de um trigger. Em geral isso acontece porque a pessoa que criou o trigger precisava realizar algum tipo de processamento para cada uma das linhas, como incluí-las em uma tabela de log. E como um trigger é disparado cada vez que uma instrução é executada tem-se uma perda de desempenho e recursos consideráveis quando se coloca um trigger dentro de um cursor.
Para substituir os cursores dentro de um trigger é preciso analisar o código e ver exatamente o que está acontecendo. Veremos um exemplo então. O código da listagem 1 apresenta um trigger que contém um cursor.
CREATE TRIGGER TRG_INS_T_CELULA ON T_CELULA FOR INSERT
AS
BEGIN
DECLARE @MAX_CELULA INT
DECLARE @CELULA_CODIGO INT
SELECT @MAX_CELULA = MAX(CELULA_CODIGO)+1
FROM T_CELULA
IF @MAX_CELULA IS NULL
SET @MAX_CELULA = 1
DECLARE C CURSOR FOR
SELECT CELULA_CODIGO
FROM INSERTED
OPEN C
FETCH NEXT FROM C
INTO @CELULA_CODIGO
WHILE( @@FETCH_STATUS = 0)
BEGIN
UPDATE T_CELULA
SET CELULA_CODIGO = @MAX_CELULA
WHERE CELULA_CODIGO = @CELULA_CODIGO
FETCH NEXT FROM C
INTO @CELULA_CODIGO
END
CLOSE C
DEALLOCATE C
END
Listagem 1. Trigger de inclusão com cursor.
O que o trigger TRG_INS_T_CELULA faz é obter o maior valor da coluna CELULA_CODIGO e depois somar um. Caso a tabela esteja vazia o código atribui o valor 1 para a variável @MAX_CELULA. Em seguida é feito um cursor para ler linha-a-linha todos os valores da tabela INSERTED. Dentro do loop a instrução UPDATE é utilizada para atualizar as linhas da tabela T_CELULA.
Para trocar o cursor do trigger da listagem 1 basta lembrar que podemos utilizar mais de uma tabela na cláusula UPDATE, ou seja, podemos substituir todos os upates realizados por apenas uma instrução que fará um join com a tabela INSERTED, que existe apenas dentro do trigger. Além disso podemos utilizar a função ISNULL() para verificar se há alguma linha na tabela quando desejamos obter o maior valor. Na listagem 2 temos o trigger sem o cursor, porém mantendo a funcionalidade original.
/**************************************************************/
/* NOVA VERSAO DO TRIGGER TRG_INS_T_CELULA
Descrição: Ajustes de desempenho: retirada de trigger */
ALTER TRIGGER TRG_INS_T_CELULA ON T_CELULA FOR INSERT
AS
BEGIN
-- TROCA DE CURSOR POR UM UPDATE COM JOIN
UPDATE T_CELULA
SET
CELULA_CODIGO = (
SELECT ISNULL(MAX(CELULA_CODIGO)+1,1) FROM T_CELULA
)
FROM T_CELULA A, INSERTED B
WHERE A.CELULA_CODIGO = B.CELULA_CODIGO
END
Listagem 2. Código fonte do trigger TRG_INS_T_CELULA sem cursor.
Constraints FK duplicadas
Em uma consultoria recente me deparei com a seguinte situação: um relacionamento entre uma chave primária e uma chave estrangeira estava duplicado. Ou seja, haviam duas constraints de chave estrangeira que tinham o mesmo propósito! Procurei tentar entender qual a lógica disto mas não fui capaz. As duas constraints estavam iguais e, fora o nome, não havia nada que diferenciava uma da outra.
Em outras palavras não havia necessidade da segunda constraint. Provavelmente isso aconteceu porque os desenvolvedores, ou quem criou o modelo, efetuou a operação de criação de constraint duas vezes ou algo assim. Além de tornar o modelo mais difícil para se compreender, repetir esta constraint pode causar problemas de desempenho durante a modificação das linhas na tabela. Neste caso a solução mais fácil foi procurar os relacionamentos duplicados e excluí-los o mais rápido possível.
Uso ineficiente de índices
O uso ineficiente de índices é outra situação que encontro com freqüência quando presto consultoria. Muitos desenvolvedores, e mesmo DBAs, criam índices de forma errada, desnecessários, e muitas vezes sem nenhum critério. Este tipo de atitude gera problemas de desempenho, consumo excessivo de recursos, falhas e pode até fazer com que o banco de dados inteiro fique indisponível.
Para citar um exemplo, houve uma vez que eu estava procurando o motivo pelo qual um banco de dados estava crescendo de tamanho de forma anormal, algo como 500 MB por semana, sem que houvesse uma razão aparente.
Analisando os dados do modelo pude perceber que a maior tabela ocupava mais da metade da base, com 20 GB e 40 milhões de linhas. Destes 20 GB que a tabela ocupava aproximadamente metade era ocupada apenas pelos índices, pois a esta tabela tinha 14 índices incluindo a chave primária. Analisando mais profundamente descobri que dois dos índices foram criados para colunas que continham apenas valores NULL e que não eram utilizados em nenhuma consulta. Resultado: estes índices estavam ocupando espaço desnecessário e prejudicavam o desempenho quando alguma linha era inserida, alterada ou excluída da tabela.
Senha do login sa em branco
Neste item temos uma questão de segurança. Não raro encontro diversos ambientes de bancos de dados com problemas de segurança e vulneráveis a ataques. Isso geralmente acontece porque os responsáveis pela segurança ou não sabem corretamente como implementá-la ou simplesmente acabam concedendo direitos além dos necessários para um usuário ou login.
O SQL Server 2000, em particular, sofre do problema da senha do login sa em branco. Graças a um check box na instalação é possível deixar a senha do principal login administrativo do SQL Server em branco tornando o banco de dados e todo o ambiente vulnerável. Além disso, o SQL Server 2000 não faz diferenciação entre letras maiúsculas e minúsculas na senha, característica que foi modificada sensivelmente no SQL Server 2005.
Isso me lembra de uma consultoria na qual fui chamado para acompanhar a implantação de um novo sistema. O responsável pela implantação disse-me que só poderia instalar os componentes se a senha do sa estivesse em branco. Na hora protestei dizendo que isso seria uma grande brecha de segurança. Sugeri a criação de um novo login ou mesmo deixar a senha do sa em branco apenas durante a instalação do sistema. Mas não teve jeito: graças a este requisito indesejável tive que deixar a senha do sa em branco senão o sistema não poderia ser instalado. Isso deixa claro a falta de preocupação com a segurança do banco de dados por parte de alguns profissionais.
Abandono de servidor
O abandono e a falta de monitoria e manutenção é um assunto muito sério que as empresas nem sempre se dão conta. As vezes parece que os profissionais pensão que um banco de dados é como uma planta: deixam ele em um canto e esperam que ele faça o seu trabalho sozinho e sem manutenção. As vezes até esquecem de molhar a planta, ou seja, verificar como anda o status do banco de dados e dos seus recursos.
Devido às características de diversos sistemas é importante sempre monitorar de perto um banco de dados. Pode ser para evitar que o disco seja preenchido totalmente ou para checar se o servidor está consumindo 100% do processador por causa do banco de dados, não importa. O que deve ser colocado como prioridade é a observação do banco de dados periodicamente para evitar ser pego desprevenido em caso de problemas.
Já cheguei a acessar um servidor remotamente e notar que há pelo menos seis meses ninguém fazia uma faxina periódica no servidor. Isso quer dizer que ninguém verificava se os logs estavam com alguma mensagem de erro, se o Transacion Log estava cheio, se a rotina de backup era adequada, se algum job falhou, se era preciso fazer um expurgo na base e outras tarefas que não são essenciais para a operação, mas que precisam ser realizadas periodicamente.
Lentidão
Com certeza problemas de lentidão são o motivo número 1 para um consultoria em banco de dados. É comum encontrar problemas de lentidão que supostamente são causados pelo banco de dados em uma consultoria, o que geralmente faz com que a empresa procure um profissional específico para cuidar desta situação.
Um cenário típico: após um período de desenvolvimento um sistema foi implantando na empresa com relativo sucesso. Algumas modificações aqui e ali e o sistema está sendo utilizado sem grandes problemas. Após um tempo considerável a aplicação começa a demorar um pouco. Os usuários notam mas não reclamam. Com o tempo a situação vai piorando: a tarefa que era executada quase que instantaneamente agora leva minutos. Os desenvolvedores são notificados e fazem pequenas modificações na aplicação ou logo de cara sugerem a compra de um hardware melhor. Geralmente isso melhora um pouco ou quase nada o desempenho, mas em poucos dias a situação se agrava. Chega um pouco que a lentidão do sistema começa a atrapalhar a operação da empresa.
Já cansei de encontrar cenários como acima. Talvez pela falta de preparo para realizar um tunning de banco de dados ou pela pressa por soluções rápidas muitas empresas simplesmente começam a se preocupar com desempenho apenas quando ele atinge um nível crítico, o que pode ser tarde demais. Em poucas palavras basta dizer que problemas de desempenho são o campeão de pesadelos (e também a principal fonte de trabalho!) para qualquer DBA ou consultor de banco de dados.
Péssima tipagem
Um problema que venho encontrando cada vez mais é a tipagem de dados errada. Esta questão envolve diretamente os desenvolvedores, programadores, analistas, modeladores, etc pois são eles os responsáveis pela criação dos tipos de dados das colunas de uma tabela.
Um exemplo simples: muitos desenvolvedores adoram o tipo de dados INT do SQL Server. Precisa armazenar um valor numérico? Bota o tipo de dados INT então! Nem que seja para armazenar a idade de uma pessoa, que raramente vai passar do valor numérico 100.
Esse é um erro com graves conseqüências. Primeiro porque escolher o tipo de dados errado vai gerar problemas de desempenho, consumo excessivo de disco, memória, processador e rede. Segundo porque modelar algo errado é um dos passos que leva a vários problemas na prototipação, programação, testes, implementação e treinamento. E terceiro porque isso dá um trabalho do caramba para resolver!
O meu conselho aqui é pensar muito bem antes de escolher o tipo de dados, pois isso é tão importante quando escolher qual tabela deve ser criada no modelo. Procurar se informar qual é o melhor tipo de dado assim como suas características vale muito mais a pena do que simplesmente escolher um tipo de dado baseado no conceito de que ou é texto ou é número ou é data.
Falta de estratégia de backup
Poucas coisas são mais aterrorizadoras do que não possuir uma estratégia de backup em ambientes que precisam de uma. Infelizmente já perdi a conta de situações nas quais me deparei com um ambiente em que não havia um backup confiável e que poderia ser utilizado.
Isso é particularmente preocupante porque na maioria das vezes em que alguém sugere o uso de backup é porque a situação já está desesperadora. Seja porque algum usuário cometeu um erro sério ou porque houve uma falha de hardware, o backup deve SEMPRE ser consistente, confiável e ficar a um passo de ser restaurado. Caso contrário é bem provável que uma situação que já esteja ruim torne-se pior ainda por não haver uma contingência adequada.
Ausência de um DBA
A ausência de um DBA é uma questão cultural, no meu ponto de vista. Se muitas vezes encontro a realidade onde já é difícil a contração de um desenvolvedor para um projeto imagina então contratar um DBA, que geralmente é profissional raro no mercado e com um valor hora alto.
Bom, basta dizer que confiar bancos de dados gigantes na mão de desenvolvedores que conhecem um pouco do banco é uma péssima idéia. Não querendo desmerecer os desenvolvedores, mas na minha experiência de consultoria tenho encontrado muitas equipes de desenvolvedores atolados de trabalho e com responsabilidades muito aquém do que foram inicialmente combinadas. Querer colocar a responsabilidade de um banco de dados grande e complexo na mão de um desenvolvedor cujo principal objeto é programar é a receita para se dar mal. Por isso creio que a partir de um certo volume de dados, e de acordo com a complexidade do sistema e do banco de dados, é crucial contar com a presença de ao menos um DBA na equipe, seja ele permanente ou não.
Falta gritante de recursos de hardware e software
Hardware é caro. Hardware para servidor de banco de dados então é mais caro ainda. Infelizmente esta afirmação é uma constante que dificilmente vai ser modificada nos próximos anos. Por isso na maioria das vezes em que é necessário investir em hardware já fico preparado para montar uma defesa com argumentos, dados, estatísticas e evidências conclusivas de que realmente é necessário realizar um upgrade ou montar uma nova plataforma para atender as necessidades.
Além disso também já encontrei problemas com o custo relacionado com software. Deixando de lado a questão da pirataria, várias vezes tive a oportunidade de me deparar com locais onde a edição do SQL Server não era a edição mais recomendada para o ambiente em que ele estava sendo utilizado. Motivo? O custo envolvido na compra da edição correta. Infelizmente o máximo que podemos fazer nestes casos é provar com argumentos sólidos que é preciso investir no software também, além é claro de cruzar os dedos e esperar que isso faça algum efeito.
Bom, estas foram apenas algumas situações ruins nas quais encontrei durante consultorias de bancos de dados. Espero que ao descrevê-las poucas pessoas se identifiquem com a situações, pois caso contrário a minha hipótese de que pouca atenção vem sendo dada à área de banco de dados irá se confirmar.
De qualquer maneira, espero que a exposição de problemas como estes possam trazer à tona a gravidade de algumas situações e que esta discussão forneça um incentivo para que os responsáveis procurem soluções para os problemas o mais rápido possível.
Um grande abraço e até a próxima pessoal.
Por Mauro Pichiliani
segunda-feira, 21 de abril de 2008
Google lança hosting grátis para aplicativos
App Engine é um serviço gratuito para desenvolvedores que podem hospedar seus projetos e usar a infra-estrutura do Google. Trabalha com aplicativos em Python e concorre com serviço similar da Amazon. Você usaria?
O Google acaba de lançar um serviço chamado App Engine. A idéia é ser um serviço completo de hosting, banco de dados e servidor de arquivos com infra-estrutura e tecnologias do Google, com a oferta de uma boa quantidade de recursos gratuitos para desenvolvedores criarem seu aplicativos.
O servidor aproveita o famoso cloud computing do Google, database com BigTable e storage com o Google File System. Todas estas tecnologias são utilizadas pelo próprio Google em seus aplicativos para que sejam rápidos e facilmente escalonáveis.
Escalabilidade sem preocupação
A novidade resolve um grande problema que startups têm: como gerenciar um servidor quando se faz sucesso de uma hora para outra. Em um dia eu tenho um punhado de usuários, no outro dia eu tenho milhões, meu servidor cai, eu fico desesperado e perco os cabelos e os usuários.
Com o App Engine o desenvolvedor pode preocupar-se só em desenvolver o seu programa e deixar toda a parte de infra estrutura para o Google.
Modelo de negócio briga com Amazon
Na versão "preview" lançada, os aplicativos não podem usar mais do que 500 MB de espaço em disco, 200 milhões de megaciclos/dia de CPU, e 10 GB de banda por dia. Vocês sabem que isso não é pouco.
Outro limite é que, por enquanto, somente aplicativos desenvolvidos em Python podem rodar no servidor. Google diz que a estrutura toda é feita para suportar qualquer linguagem e que vai aos poucos liberar novas linguagens.
A idéia, quando o produto estiver pronto, é vender mais recursos para os desenvolvedores, conforme a demanda de seus aplicativos. Exatamente o que a Amazon faz com seus serviços de Storage e Cloud Computing.
A concorrência entre os dois agora será uma briga boa de assistir. Enquanto o Google entra no mercado com uma afinidade muito grande com os desenvolvedores, a Amazon já é o líder deste mercado e tem vários cases muito interessantes para mostrar.
APIs do Google para tarefas mais comuns
Além de tudo isso, o App Engine ainda dá acesso a APIs do Google para fazer tarefas comuns como autenticação de usuários e envio de e-mails. Ou seja, eu poderei usar minha conta do google para fazer login em um aplicativo hospedado no App Engine.
O serviço tem também uma ampla gama de análises de uso do servidor, de banda, de ciclos, etc, algo como o Google Analytics mas voltado para o servidor em si e não para o conteúdo. Eles dizem que estes são só os primeiros features, que ainda não estão nem perto de ter todos os features planejados para o serviço.
Isso deve mudar o cenário?
Com isso, desenvolvedores têm um custo a menos para lançarem um aplicativo. Será que isso muda o cenário da web 2.0? Será que terá um impacto grande? Você usaria o serviço?
Por Gilberto Alves Jr.
O Google acaba de lançar um serviço chamado App Engine. A idéia é ser um serviço completo de hosting, banco de dados e servidor de arquivos com infra-estrutura e tecnologias do Google, com a oferta de uma boa quantidade de recursos gratuitos para desenvolvedores criarem seu aplicativos.
O servidor aproveita o famoso cloud computing do Google, database com BigTable e storage com o Google File System. Todas estas tecnologias são utilizadas pelo próprio Google em seus aplicativos para que sejam rápidos e facilmente escalonáveis.
Escalabilidade sem preocupação
A novidade resolve um grande problema que startups têm: como gerenciar um servidor quando se faz sucesso de uma hora para outra. Em um dia eu tenho um punhado de usuários, no outro dia eu tenho milhões, meu servidor cai, eu fico desesperado e perco os cabelos e os usuários.
Com o App Engine o desenvolvedor pode preocupar-se só em desenvolver o seu programa e deixar toda a parte de infra estrutura para o Google.
Modelo de negócio briga com Amazon
Na versão "preview" lançada, os aplicativos não podem usar mais do que 500 MB de espaço em disco, 200 milhões de megaciclos/dia de CPU, e 10 GB de banda por dia. Vocês sabem que isso não é pouco.
Outro limite é que, por enquanto, somente aplicativos desenvolvidos em Python podem rodar no servidor. Google diz que a estrutura toda é feita para suportar qualquer linguagem e que vai aos poucos liberar novas linguagens.
A idéia, quando o produto estiver pronto, é vender mais recursos para os desenvolvedores, conforme a demanda de seus aplicativos. Exatamente o que a Amazon faz com seus serviços de Storage e Cloud Computing.
A concorrência entre os dois agora será uma briga boa de assistir. Enquanto o Google entra no mercado com uma afinidade muito grande com os desenvolvedores, a Amazon já é o líder deste mercado e tem vários cases muito interessantes para mostrar.
APIs do Google para tarefas mais comuns
Além de tudo isso, o App Engine ainda dá acesso a APIs do Google para fazer tarefas comuns como autenticação de usuários e envio de e-mails. Ou seja, eu poderei usar minha conta do google para fazer login em um aplicativo hospedado no App Engine.
O serviço tem também uma ampla gama de análises de uso do servidor, de banda, de ciclos, etc, algo como o Google Analytics mas voltado para o servidor em si e não para o conteúdo. Eles dizem que estes são só os primeiros features, que ainda não estão nem perto de ter todos os features planejados para o serviço.
Isso deve mudar o cenário?
Com isso, desenvolvedores têm um custo a menos para lançarem um aplicativo. Será que isso muda o cenário da web 2.0? Será que terá um impacto grande? Você usaria o serviço?
Por Gilberto Alves Jr.
quinta-feira, 17 de abril de 2008
COM.BR com CPF
Prezado(a) Usuário(a),
COM.BR com CPF
--------------
Por decisão do CGI.br, o domínio COM.BR, destinado a atividades
comerciais genéricas na Internet, também poderá ser registrado sob um
CPF. Ou seja, pessoas naturais com atividades comerciais e afins
poderão registrar domínios COM.BR.
Esta modificação terá efeito a partir do dia 01/05/2008.
Inicialmente, somente o domínio COM.BR estará disponível nesta nova
categoria, genérica, que permite registro tanto com CNPJ quanto com
CPF. Lembramos que, para manter a transparência do registro de
domínios .br, pessoas físicas responsáveis por domínios COM.BR estarão
sujeitas aos mesmos procedimentos das entidades cadastradas
previamente.
Verificação DNS
---------------
O Registro.br monitora constantemente o correto funcionamento de seus
domínios. Fique atento aos avisos de problemas DNS e siga nossas
recomendações para evitar problemas aos usuários de seus sítios.
Agradecemos a atenção,
Registro.br
http://registro.br/
COM.BR com CPF
--------------
Por decisão do CGI.br, o domínio COM.BR, destinado a atividades
comerciais genéricas na Internet, também poderá ser registrado sob um
CPF. Ou seja, pessoas naturais com atividades comerciais e afins
poderão registrar domínios COM.BR.
Esta modificação terá efeito a partir do dia 01/05/2008.
Inicialmente, somente o domínio COM.BR estará disponível nesta nova
categoria, genérica, que permite registro tanto com CNPJ quanto com
CPF. Lembramos que, para manter a transparência do registro de
domínios .br, pessoas físicas responsáveis por domínios COM.BR estarão
sujeitas aos mesmos procedimentos das entidades cadastradas
previamente.
Verificação DNS
---------------
O Registro.br monitora constantemente o correto funcionamento de seus
domínios. Fique atento aos avisos de problemas DNS e siga nossas
recomendações para evitar problemas aos usuários de seus sítios.
Agradecemos a atenção,
Registro.br
http://registro.br/
terça-feira, 15 de abril de 2008
Usuários protestam contra aposentadoria do Windows XP
Milhares de usuários do Windows XP, da Microsoft, estão protestando contra a retirada de circulação do sistema operacional, marcada para junho.
A empresa deixará de vender o Windows XP para estimular o uso do Vista, nova versão do programa que já possui mais de um ano de mercado, mas não convenceu muitos especialistas e usuários. A companhia fornecerá, até abril de 2009, apoio técnico para aqueles que continuarão usando o antigo sistema operacional --a partir dessa data, prestará um nível mínimo de assistência.
Usuários do Windows XP não estão dispostos a deixar o sistema operacional e já recolheram mais de 140 mil assinaturas em um pedido on-line contra a aposentadoria da versão.
Segundo estimativas do grupo de pesquisa de mercado IDC, em torno de 60% dos computadores particulares e 70% dos utilizados em empresas ainda funcionam com o XP.
A Microsoft, que está trabalhando em uma nova versão de seu sistema operacional --chamada, por enquanto, de Windows 7--, já adiou em outra ocasião a retirada do XP, mas afirmou que não vai prolongar o prazo desta vez.
"Não há planos para estender a venda do Windows XP para além de 30 de junho de 2008", disse Michael Dix, diretor-geral de gestão de produtos para clientes da Microsoft, no site corporativo da empresa.
A empresa deixará de vender o Windows XP para estimular o uso do Vista, nova versão do programa que já possui mais de um ano de mercado, mas não convenceu muitos especialistas e usuários. A companhia fornecerá, até abril de 2009, apoio técnico para aqueles que continuarão usando o antigo sistema operacional --a partir dessa data, prestará um nível mínimo de assistência.
Usuários do Windows XP não estão dispostos a deixar o sistema operacional e já recolheram mais de 140 mil assinaturas em um pedido on-line contra a aposentadoria da versão.
Segundo estimativas do grupo de pesquisa de mercado IDC, em torno de 60% dos computadores particulares e 70% dos utilizados em empresas ainda funcionam com o XP.
A Microsoft, que está trabalhando em uma nova versão de seu sistema operacional --chamada, por enquanto, de Windows 7--, já adiou em outra ocasião a retirada do XP, mas afirmou que não vai prolongar o prazo desta vez.
"Não há planos para estender a venda do Windows XP para além de 30 de junho de 2008", disse Michael Dix, diretor-geral de gestão de produtos para clientes da Microsoft, no site corporativo da empresa.
KML agora é padrão de compartilhamento de mapas
O formato KML (Keyhole Markup Language) , difundido no mundo pela Google junto com o Google Earth, foi oficialmente transformado em um formato padrão de localização geográfica no compartilhamento de mapas pela Open Geospatial Consortium.

"Segundo o Google existe hoje mais de 10 milhões de arquivos KML espalhados pelo mundo. O fato do formato KML tornar-se um padrão internacional só alimenta o estímulo de permitir com que outras aplicações sejam criadas, aproveitando-se de um formato já amplamente implementado nas aplicações do Google. Agora só falta o Yahoo e Microsoft, dentre outras empresas, permitirem com que o KML seja usado para compartilhar informações sobre os aplicativos de mapas que eles oferecem." - citou Henrique Costa Pereira do Blog Revolução.etc.br.
"Segundo o Google existe hoje mais de 10 milhões de arquivos KML espalhados pelo mundo. O fato do formato KML tornar-se um padrão internacional só alimenta o estímulo de permitir com que outras aplicações sejam criadas, aproveitando-se de um formato já amplamente implementado nas aplicações do Google. Agora só falta o Yahoo e Microsoft, dentre outras empresas, permitirem com que o KML seja usado para compartilhar informações sobre os aplicativos de mapas que eles oferecem." - citou Henrique Costa Pereira do Blog Revolução.etc.br.
sábado, 12 de abril de 2008
Browsers - Guerra Fria
Quando o Netscape e o Internet Explorer faziam a Guerra dos Browsers o principal objetivo era conquistar usuários. As formas que os dois utilizavam para adquirir adeptos eram prejudiciais para o desenvolvimento web. Basicamente o que os browsers faziam era criar códigos proprietários. Isso gerava um retrabalho terrível para os desenvolvedores. Se você tivesse 10 sites para gerenciar, na verdade seriam 20, por conta de ter a necessidade de haver uma versão para Netscape e outra para Internet Explorer. Isso gerava trabalho em dobro. Se houvesse alguma modificação no layout, texto ou programação, o desenvolvedor teria que atualizar as duas versões dos sites.
Era normal que o visitante ao entrar nos sites via dois logos: um do Netscape e outro logo do Internet Explorer e a seguinte frase: “Qual browser você utiliza?” Então o usuário escolhia qual browser ele utilizava e clicava no link que o levava para um site desenvolvido especialmente para aquele browser.
A idéia era simples: se a grande maioria dos usuários utilizassem o Netscape, por exemplo, os desenvolvedores seriam obrigados a desenvolver em primeiro lugar para o Netscape e deixar o Internet Explorer em segundo plano.
O problema é que essa guerra estava ficando insuportável para os desenvolvedores. Desenvolver para web estava ficando muito caro. Ter um site simples publicado custava caro e o desenvolvimento era demorado e confuso.
Felizmente essa guerra acabou. Hoje os fabricantes de browsers estão com outro pensamento. A guerra de hoje é mais silenciosa e agrega muito mais valor ao desenvolvimento web. Os métodos para conquistar usuários é direcionada em serviços. Sim, ainda é mais difícil conseguir os usuários mais leigos, mas essa massa está se renovando e novos usuários de internet já sabem qual browser escolher e os motivos para escolhê-lo.
Internet Explorer 8, Safari 3.1 e Firefox 3 estão se esforçando para alcançar o nível máximo de suporte aos Padrões. Isso conquista o desenvolvedor que por sua vez vai evangelizar o usuário leigo a utilizar o browser mais interessante e útil para as necessidades dele.
Agora, o objetivo mais difícil ainda precisa ser cumprido: convencer os desenvolvedores a utilizar os Padrões Web. Com certeza este é o caminho mais complicado. Pelo menos, se não for por bem, vai por livre e espontânea pressão. A seleção natural infalível do mercado cuidará desses.
Autor: Diego Eis
Fonte: http://www.tableless.com.br/
Era normal que o visitante ao entrar nos sites via dois logos: um do Netscape e outro logo do Internet Explorer e a seguinte frase: “Qual browser você utiliza?” Então o usuário escolhia qual browser ele utilizava e clicava no link que o levava para um site desenvolvido especialmente para aquele browser.
A idéia era simples: se a grande maioria dos usuários utilizassem o Netscape, por exemplo, os desenvolvedores seriam obrigados a desenvolver em primeiro lugar para o Netscape e deixar o Internet Explorer em segundo plano.
O problema é que essa guerra estava ficando insuportável para os desenvolvedores. Desenvolver para web estava ficando muito caro. Ter um site simples publicado custava caro e o desenvolvimento era demorado e confuso.
Felizmente essa guerra acabou. Hoje os fabricantes de browsers estão com outro pensamento. A guerra de hoje é mais silenciosa e agrega muito mais valor ao desenvolvimento web. Os métodos para conquistar usuários é direcionada em serviços. Sim, ainda é mais difícil conseguir os usuários mais leigos, mas essa massa está se renovando e novos usuários de internet já sabem qual browser escolher e os motivos para escolhê-lo.
Internet Explorer 8, Safari 3.1 e Firefox 3 estão se esforçando para alcançar o nível máximo de suporte aos Padrões. Isso conquista o desenvolvedor que por sua vez vai evangelizar o usuário leigo a utilizar o browser mais interessante e útil para as necessidades dele.
Agora, o objetivo mais difícil ainda precisa ser cumprido: convencer os desenvolvedores a utilizar os Padrões Web. Com certeza este é o caminho mais complicado. Pelo menos, se não for por bem, vai por livre e espontânea pressão. A seleção natural infalível do mercado cuidará desses.
Autor: Diego Eis
Fonte: http://www.tableless.com.br/
quarta-feira, 9 de abril de 2008
Como colocar sua empresa no Google Maps
Que tal colocar sua empresa no Google Maps? Afinal, lista telefônica já está se tornando coisa do passado!

A Google iniciou, no ano passado, a aceitar localização de empresas enviadas pelos usuários. Assim, qualquer um que quisesse colocar no Maps informações mais detalhadas de sua empresa, poderia simplesmente enviar as informações por um formulário, no site do Maps. O problema é que para nós, brasileiros, o recurso não estava disponível. Embora fosse possível fazer buscas por empresas, devido a convênios feitos com alguns serviços nacionais, não era permitido fazer o cadastro da empresa.
Hoje, o leitor Rodrigo Lóssio nos avisou que já está disponível a opção de cadastro de empresas nacionais no Google Maps. Para colocar sua empresa no Google Maps, basta visitar a página do Google Local Business Center e preencher o formulário com todas as informações necessárias.
Além de localizar a empresa, colocando o endereço, é possível fornecer telefone, o site da empresa, outras formas de contato, um breve descritivo, fotos, logomarca, horário de funcionamento, entre outras informações. É possível, inclusive, fazer resenhas da empresa, como comentários do atendimento ou dos serviços prestados, por exemplo.
Segundo o Rodrigo, que já fez o cadastro de sua empresa, para confirmar o inclusão dos dados, é feita no momento uma ligação telefônica, com gravação em português, e você informa um código exposto na tela. Pode-se ainda confirmar por SMS ou por carta.
Charsets e Encodes - Tabelas de caracteres
Quando você escreve um documento HTML (ou qualquer outra linguagem baseada em SGML) é necessário que especifiquemos o Charset utilizado. O Charset é o conjunto de caracteres utilizados para escrever o documento. Um jogo de caracteres consiste em ter 1) repertório com caracteres como a letra “A” ou o caractere Chinês que significa “água” e 2) uma posição de referência para cada um dos caracteres no repertório. Cada caractere é identificado e localizado por este código de posição. Por exemplo, na tabela ASCII, as posições 65, 66 e 67 se referem às letras A, B e C respectivamente.
A tabela de caracteres ASCII (Código Padrão Americano para Intercâmbio de Informações) foi a primeira tabela utilizada em larga escala. O computador foi desenvolvido nos Estados Unidos. No vocabulário americano, não existem acentos, além disso, era um código de 7 bits, e não 8. Ou seja, ao invés de 256 posições, a tabela ASCII tinha apenas 128 posições - como você sabe, tudo nos computadores são um grupo de zeros (0) e uns (1) chamados de bits. Esses zeros e uns formam grupos de oito em oito que chamados de bytes e representam um número entre 0 e 255. Como as imagens, áudio, vídeos, programas e tudo o que temos nos sistemas de hoje, os caracteres que aparecem na sua tela são grupos de zeros e uns.
O computador se popularizou e a necessidade de utilizar acentos e outros tipos de caracteres (Chineses, por exemplo) tornou-se um problema.
Hoje, a maioria das tabelas utilizadas foram criadas suprindo as necessidades de um idioma específico, por este motivo elas se tornaram muito limitadas.
Por exemplo, se você estiver escrevendo um documento utilizando a tabela de caracteres chinesa, você não poderá escrever algo em hebraico neste documento.
Por conta disso muitos problemas podem surgir, por exemplo, seria impossível criar um curso online de hebraico para chineses. Será também um problema se você tiver que fazer um site ou sistema com suporte a diversos idiomas. Por exemplo, um sistema de blog projetado para uso internacional. Isso por que a posição dos caracteres varia de tabela para tabela. Dois codificadores podem usar o mesmo número para dois caracteres diferentes ou usar números diferentes para o mesmo caractere.
A Web é acessada por pessoas do mundo inteiro. Ter um sistema ou um site que limite o acesso e pessoas de outros países é algo que vai contra a tradição e os ideais da internet. Por isso, foi criado uma tabela que suprisse essas necessidades, essa tabela se chama Unicode. A tabela Unicode suporta algo em torno de um milhão de caracteres. Ao invés de cada região ter sua tabela de caracteres, é muito mais sensato haver uma tabela padrão com o maior número de caracteres possível. Atualmente a maioria dos sistemas e browsers utilizados por usuários suportam plenamente Unicode. Por isso, fazendo seu sistema Unicode você garante que ele será bem visualizado aqui, na China ou em qualquer outro lugar do mundo.
O que o Unicode faz é fornecer um único número para cada caractere, não importa a plataforma, nem o programa, nem a língua.
A tabela de caracteres ASCII (Código Padrão Americano para Intercâmbio de Informações) foi a primeira tabela utilizada em larga escala. O computador foi desenvolvido nos Estados Unidos. No vocabulário americano, não existem acentos, além disso, era um código de 7 bits, e não 8. Ou seja, ao invés de 256 posições, a tabela ASCII tinha apenas 128 posições - como você sabe, tudo nos computadores são um grupo de zeros (0) e uns (1) chamados de bits. Esses zeros e uns formam grupos de oito em oito que chamados de bytes e representam um número entre 0 e 255. Como as imagens, áudio, vídeos, programas e tudo o que temos nos sistemas de hoje, os caracteres que aparecem na sua tela são grupos de zeros e uns.
O computador se popularizou e a necessidade de utilizar acentos e outros tipos de caracteres (Chineses, por exemplo) tornou-se um problema.
Hoje, a maioria das tabelas utilizadas foram criadas suprindo as necessidades de um idioma específico, por este motivo elas se tornaram muito limitadas.
Por exemplo, se você estiver escrevendo um documento utilizando a tabela de caracteres chinesa, você não poderá escrever algo em hebraico neste documento.
Por conta disso muitos problemas podem surgir, por exemplo, seria impossível criar um curso online de hebraico para chineses. Será também um problema se você tiver que fazer um site ou sistema com suporte a diversos idiomas. Por exemplo, um sistema de blog projetado para uso internacional. Isso por que a posição dos caracteres varia de tabela para tabela. Dois codificadores podem usar o mesmo número para dois caracteres diferentes ou usar números diferentes para o mesmo caractere.
A Web é acessada por pessoas do mundo inteiro. Ter um sistema ou um site que limite o acesso e pessoas de outros países é algo que vai contra a tradição e os ideais da internet. Por isso, foi criado uma tabela que suprisse essas necessidades, essa tabela se chama Unicode. A tabela Unicode suporta algo em torno de um milhão de caracteres. Ao invés de cada região ter sua tabela de caracteres, é muito mais sensato haver uma tabela padrão com o maior número de caracteres possível. Atualmente a maioria dos sistemas e browsers utilizados por usuários suportam plenamente Unicode. Por isso, fazendo seu sistema Unicode você garante que ele será bem visualizado aqui, na China ou em qualquer outro lugar do mundo.
O que o Unicode faz é fornecer um único número para cada caractere, não importa a plataforma, nem o programa, nem a língua.
- Cabeçalho HTTP Content-type - Desta forma é necessário configurar o servidor web, algo que não é fácil nem para qualquer um. Dependendo de onde você trabalha, se for em um lugar grande, com vários sites neste mesmo servidor, pode ser a melhor maneira porque você terá que fazer isso uma vez. Caso for vários projetos com servidores diferentes isso pode ser uma dor de cabeça.
- Metatag Content-type - Colocando este código no HEAD de seu documento, ele avisará para o browser localmente e na hora da renderização do site qual Charset ele deve utilizar para exibir os caracteres. Esta é uma ótima escolha caso você não tenha acesso aos servidores. Certamente é a maneira mais simples de ser utilizada.
- Através do prolog xml - O prolog XML é utilizado em documentos XML ou XHTML para indicar a versão e a tabela de caracteres daquele documento.
Se um projeto já está no ar, é bom fazer uma análise para ter certeza se vale a pena ou não mudar a tabela de um projeto que já está no ar e funcionando. Recomendo que esse novo padrão sempre comece a ser utilizado em novos projetos. Mesmo assim, um bom programador pode fazer um script que converta a tabela de caracteres de um diretório inteiro.
O importante é garantir que seu site aqui seja visto da maneira correta em outros lugares do mundo. Isso é importante para você e seu cliente.
Fonte: www.tableless.com.brsegunda-feira, 7 de abril de 2008
A cotação dos Browsers
A Net Application vem divulgando mensalmente as estatísticas de acesso na web, desde SOs a Browsers, é notável como o Firefox vem crescendo gradativamente no mundo... aí vão os dados:
janeiro 2008
acompanhe você mesmo...
http://marketshare.hitslink.com/
janeiro 2008
- IE-75,47
- FF-16,98
- IE-74,88
- FF-17,27
- IE-74,80
- FF-17,83
- IE-70,02
- FF-22,93
acompanhe você mesmo...
http://marketshare.hitslink.com/
IE8 - O sonho não acabou
A Microsoft voltou atrás com a decisão do Browser Targeting Version. Eles decidiram que, por padrão, o IE8 irá renderizar os sites no modo mais complacente com os Padrões Web possível, esse modo está sendo chamado de “Super Standards Mode”. Se você não desenvolve com Padrões, comece a se preocupar.
A idéia de nivelar tudo por cima, para mim, sempre foi o melhor caminho. Se você não desenvolve com Padrões, ou se desenvolve despreocupadamente, é melhor mudar. Caso você se encaixe neste perfil, há duas opções:
1. Ou você aplica o Browser Targeting Version. Isso fará com que o IE8 utilize o motor de renderização do IE7. 2. Ou pára de preguiça e aprende de uma vez por todas a fazer sites padronizados. Para mim, este é o melhor caminho.
Fazer um browser rigoroso, faz com que o mercado saia da zona de conforto e comece a pensar. Tudo sobe um nível e a coisa fica mais interessante. Mesmo a decisão sendo boa, a galera ainda tem um pé atrás (leia os comentários).
As atualizações do IE8 são ótimas. Há uma série de características que fazem muita falta no IE6 e no IE7 e que agora farão parte do IE8. Por exemplo, as pseudo-classes :before, :after e :focus. A propriedade content, que serve para gerar conteúdo, também estará nessa nova atualização. Entre outras facilidades que antes usávamos apenas em browsers como Firefox, Opera e Safari.
Me preocupo com o momento em que o IE6, IE7 e IE8 estarão sendo utilizados pelos visitantes, aí sim teremos um grande problema. Ou três.
Fonte: http://www.tableless.com.br
Configurando o Plugin do Aptana no Eclipse
Olá pessoal da elógica. Após o workshop de hoje, fiz um rápido tutorial sobre como instalar o plugin do Aptana no Eclipse. Muito fácil, rápido e Free!
URL do Instalador do Aptana: http://update.aptana.com/update/3.2/site.xml
Aproveitem!
Traduza automaticamente planilhas do Google Spreadsheets
Logo após o lançamento da API de tradução automática da Google, já surgiu um Gadget super interessante para o Google Spreadsheets. Trata-se de um Gadget que faz tradução automática de idiomas de planilhas inteiras do Spreadsheets.
Graças a nova possibilidade do Google Docs ser integrado com Gadgets, você pode adicionar a seguinte URLnas opções de Gadgets e o conteúdo selecionada da planilha será automaticamente traduzido para o idioma selecionado.
O interessante é que a tradução é instantânea, fazendo com que qualquer alteração na planilha faça o Gadget atualizar automaticamente. Isso torna o processo um pouco chato, já que o Gadget perde um bom tempo carregado, porém é extremamente útil para acompanhar e, porque não, montar uma planilha em inglês ou qualquer outro idioma, utilizando o Gadget como um um tradutor prático.
Como o Gadget é publicado junto com a planilha, você pode enviar para um amigo ou publicar na Web a versão da planilha em mais de um idioma.
http://spreadsheets.google.com/pub?key=pma6ubDfcbBcLkGb_8WXHRQ
fonte: nandokanarski
Graças a nova possibilidade do Google Docs ser integrado com Gadgets, você pode adicionar a seguinte URLnas opções de Gadgets e o conteúdo selecionada da planilha será automaticamente traduzido para o idioma selecionado.
O interessante é que a tradução é instantânea, fazendo com que qualquer alteração na planilha faça o Gadget atualizar automaticamente. Isso torna o processo um pouco chato, já que o Gadget perde um bom tempo carregado, porém é extremamente útil para acompanhar e, porque não, montar uma planilha em inglês ou qualquer outro idioma, utilizando o Gadget como um um tradutor prático.
Como o Gadget é publicado junto com a planilha, você pode enviar para um amigo ou publicar na Web a versão da planilha em mais de um idioma.
http://spreadsheets.google.com/pub?key=pma6ubDfcbBcLkGb_8WXHRQ
fonte: nandokanarski
sábado, 5 de abril de 2008
Internet revoluciona transparência pública, diz Bill Gates
O presidente da Microsoft, Bill Gates, atribuiu na sexta-feira à Internet avanços "fenomenais" na transparência das finanças dos governos, citando o caso das prestações de conta na Escandinávia.
"Os países nórdicos, com Suécia e Dinamarca, realmente levaram isso a um nível incrível", disse Gates numa conferência sobre governos na América Latina, preparatória para a reunião anual do Banco Interamericano de Comércio em Miami.
"Quando um ministro [nórdico] sai para almoçar, você pode ver quanto ele gastou no almoço e quanto no táxi. Literalmente aparece [na Internet] em poucas horas", disse ele.
Ele se referia aos registros detalhados das atividades do governo nos sites oficiais, onde constam agendas ministeriais, orçamentos e dados de concorrências públicas.
"Em cada oferta feita [nas concorrências], os autores aparecem nas redes, você vê os termos que eles oferecem", afirmou Gates, referindo-se a novos procedimentos adotados em lugares como a Suécia.
"É um processo de concorrência muito aberto, muito transparente," disse ele, acrescentando que "coisas do governo que realmente importam" agora estão acessíveis no computador de qualquer um.
"Ainda há muito a ser feito," ressalvou o empresário. "A qualidade da governança melhorou, e podem melhorar muito mais, por causa da transparência da Internet."
Nos EUA também, segundo ele, há muitos dados do governo online, mas normalmente o jargão e as dificuldades de navegação afastam a maioria dos usuários.
"É aí que os países nórdicos são melhores. Nós [os EUA] não somos modelo para esse esforço em particular", afirmou Gates, que em junho deixará suas tarefas cotidianas na Microsoft para se dedicar exclusivamente à filantropia por intermédio da sua fundação.
Fonte: Tom Brown.
"Os países nórdicos, com Suécia e Dinamarca, realmente levaram isso a um nível incrível", disse Gates numa conferência sobre governos na América Latina, preparatória para a reunião anual do Banco Interamericano de Comércio em Miami.
"Quando um ministro [nórdico] sai para almoçar, você pode ver quanto ele gastou no almoço e quanto no táxi. Literalmente aparece [na Internet] em poucas horas", disse ele.
Ele se referia aos registros detalhados das atividades do governo nos sites oficiais, onde constam agendas ministeriais, orçamentos e dados de concorrências públicas.
"Em cada oferta feita [nas concorrências], os autores aparecem nas redes, você vê os termos que eles oferecem", afirmou Gates, referindo-se a novos procedimentos adotados em lugares como a Suécia.
"É um processo de concorrência muito aberto, muito transparente," disse ele, acrescentando que "coisas do governo que realmente importam" agora estão acessíveis no computador de qualquer um.
"Ainda há muito a ser feito," ressalvou o empresário. "A qualidade da governança melhorou, e podem melhorar muito mais, por causa da transparência da Internet."
Nos EUA também, segundo ele, há muitos dados do governo online, mas normalmente o jargão e as dificuldades de navegação afastam a maioria dos usuários.
"É aí que os países nórdicos são melhores. Nós [os EUA] não somos modelo para esse esforço em particular", afirmou Gates, que em junho deixará suas tarefas cotidianas na Microsoft para se dedicar exclusivamente à filantropia por intermédio da sua fundação.
Fonte: Tom Brown.
sexta-feira, 4 de abril de 2008
Picasa Web Albums para Windows Mobile
Depois de lançar uma versão exclusiva do PicasaWeb para o iPhone, a Google resolveu abusar dos recursos do Windows Mobile 6[bb], com touchscreen, e lançou uma versão exclusiva do PicasaWeb para Windows Mobile.
A nova versão também conta com a integração com o Google Gears para celulares[bb]. Disponível somente para Windows Mobile, o Plug-in permite aos usuários utilizarem aplicações web mesmo estando sem internet.
Para visualizar o PicasaWeb em seu aparelho com Windows Mobile, visite picasaweb.google.com
A nova versão também conta com a integração com o Google Gears para celulares[bb]. Disponível somente para Windows Mobile, o Plug-in permite aos usuários utilizarem aplicações web mesmo estando sem internet.
Para visualizar o PicasaWeb em seu aparelho com Windows Mobile, visite picasaweb.google.com
(YSlow) Melhore a Performance do seu Website (Por Thiago Ferreira)
O YSlowé uma ferramenta de perfomance para web, desenvolvido pela equipe de desenvolvimento do Yahoo!. Ela segue as melhores práticas de web performance para front-end, adotadas pela equipe de performance do Yahoo!.
Seu funcionamento é integrado ao plugin FireBug, para o browser Firefox. Portanto, antes de instalar o YSlow no Firefox, é necessário instalar o Firebug.
Este artigo não é uma tradução, mas é baseado nas regras de performance do YSlow, disponíveis da documentação da ferramenta. Além de trechos de adaptados do link original, há opiniões, comentários e conclusões deste que vos "fala".
Mas, por que a performance do front-end é importante?
apenas 5% do tempo de carregamento da página é gasto com o download do código HTML. Os outros 95% são gastos com imagens, CSS, Javascripts, etc..
Uma pesquisa mostrou que 9 dos 10 maiores sites americanos têm, no máximo, 20% do tempo de carregamento gasto com HTML.
Isso nos indica que devemos cuidar da performance do front-end das nossas páginas WEB, a fim de melhorar a experiência do visitante.
As três principais razões para começar pela performance do front-end, segundo os especialistas em performance do Yahoo!:
Para medir a performance de uma página, o YSlow basea-se em 13 regras. De acordo com a taxa de aderência da página às regras, é dada uma pontuação de A a F para cada regra, onde A representa a nota máxima e F representa a nota mínima. Também é calculada a nota final, com a média das notas obtidas nas 13 regras.
O detalhamento das notas para cada página pode ser vista na aba Performance, do YSlow.
Algumas dessas regras, como veremos a seguir, são proibitivas para a maioria dos sites devido ao custo, complexidade ou freqüência de uso. Vamos às regras!
Regras para Alta Performance
As regras são classificadas de acordo com o seu grau de importância.
Regra 1: Fazer poucas requisições HTTP
Segundo Steve Souders, que é o CARA do time de performance do Yahoo!, 80% do tempo gasto por um usuário numa página é carregando o front-end e que a maior parte desse tempo de carregamento é tomado pelo download de imagens, scripts, css, flash, etc., como já vimos anteriormente.
Então, para melhorar a performance no carregamento da página é importante utilizarmos o menos possível de imagens, css, etc. Para isso, além de otimizar essas requisições fazendo somente as necessárias, pode-se utilizar técnicas citadas por ele:
CDN (Content Delivery Network) pode ser traduzido como "Entregador de Conteúdo na Rede". Embora a (má) tradução tenha dificultado o entendimento, isso é simples de entender. Digamos que você tenha um site de acesso global, como YouTube. Suponha que os arquivos estejam num único servidor aqui no Brasil. Agora imaginem os usuários de outros países e continentes acessando esse conteúdo. O caminho é longo, certo? Caminho longo significa maior tempo para acesso e carga desses arquivos.
O CDN serve justamente para eliminar isso, pois trata-se de uma coleção de servidores de conteúdo distribuídos geográficamente, de forma a minimizar a distância entre o usuário e o conteúdo estático de seu site. O cálculo de proximidade entre usuário e conteúdo é calculado através de saltos (hops) de roteamento ou do tempo de resposta à solicitação.
Mas como eu havia dito antes, há regras do YSlow que são proibitivas pelo custo. Esse é o caso da Regra 2 que, além de ser cara, só é necessário para uma parcela pequena de sites.
Regra 3: Adicione Expires no cabeçalho
O cabeçalho Expires diz ao browser a data que os componentes daquela requisição irão expirar, ou seja, se você determina um prazo de 5 anos para uma página expirar, todos componentes nela contidos somente expirarão em 5 anos. Com isso, todos os componentes (imagens, CSS, scripts, Flash, etc.) serão colocados em cache e, nas próximas visitas, o número de requisições HTTP será menor pois os componentes poderão ser acessados diretamente do cache do browser.
Aí você pergunta: "Mas e se eu fizer uma alteração num componente?". Se você fizer uma alteração, precisará alterar também o nome deste componente. É altamente recomendado que seja acrescentado nos nomes dos componentes informações de versão. Exemplo: estilo_1.css.
Quando você fizer uma alteração neste arquivo, basta alterar a numeração da versão, colocando estilo_2.css.
O uso da linha de código a seguir faz com que os componentes da página que a contém expirar somente em 2012.
[code][/code]
Acontece que o HTTP/1.1 não recomenda o uso de datas de expiração maiores do que um ano. Eu penso que realmente não há necessidade de ser maior do que um ano pois normalmente os caches são limpos pelos usuários com freqüência.
Não recomendo o uso dessa técnica durante o desenvolvimento do projeto pois será mais difícil corrigir bugs e fazer alterações.
Regra 4: Compacte componentes
Esta regra de performance indica que é recomendado que os componentes sejam compactados através da requisição HTTP para que o tempo de resposta seja menor, fazendo com que os componentes sejam carregados mais rapidamente no cliente.
A configuração da forma de compactação e o algoritmo de compactação utilizados variam de acordo com o servidor WEB utilizado.
A compactação é recomendada para qualquer arquivo de texto, como HTML, Javascript, folhas de estilo, XML, JSON, etc. Ela só não é recomendada para alguns tipos de arquivos como imagens e PDF, pois eles já são comprimidos e a compactação seria ineficiente e tomaria recursos do servidor desnecessariamente.
Regra 5: Coloque o CSS no topo
Essa é uma das regras mais simples de seguir. Ela diz que a declaração das folhas de estilo (CSS) deve estar dentro do HEAD do documento. Isso é um tanto quanto óbvio, pois a especificação do HTML já diz isso.
O CSS deve estar no HEAD pois o browser pode renderizar o conteúdo de acordo com a progressão do carregamento dos componentes. Isso trás melhor experiência ao usuário pois ele, além de ver que algo está acontecendo, pode acessar um link que já tenha aparecido no browser antes mesmo da página terminar de carregar.
Quando o CSS não está no HEAD, alguns browsers esperam todo o carregamento da página, para que não tenha que haver reposicionamento ou redesenho de componentes. Enquanto não aparecem, o usuário vê somente uma página em branco. Browsers como o Firefox, que mostram o conteúdo independente do local de declaração do CSS, "correm o risco" de ter que redesenhar ou reposicionar os componentes na tela.
Regra 6: Coloque os scripts embaixo
Os arquivos externos de javascript funcionam da forma contrária aos arquivos CSS, quanto à renderização progressiva. Enquanto o CSS bloqueia a renderização de tudo o que está antes dele até seu carregamento completo, o javascript bloqueia o carregamento de tudo o que está depois dele, até o seu carregamento.
Assim, se você colocar os arquivos de script o mais próximo possível da tag de fechamento do BODY, a renderização de tudo o que está antes do script poderá ser feita independente do carregamento desses arquivos.
Outro fator que justifica a colocação dos scripts tão próximo do fechamento de BODY quanto possível é que os browsers não fazem download de nenhum outro arquivo enquanto fazem o download de um script javascript, independente se é do mesmo servidor ou não.
Eu até achava que os scripts não poderiam ser colocados dentro do BODY, mas, depois que li essa regra, fiz uma pesquisa e constatei que a especificação do HTML não tem nenhuma contra-indicação quanto a isso.
Regra 7: Evite expressões CSS
É possível declarar expressões em CSS através do método expression. Uma expressão CSS utiliza javascript para calcular algum valor que será utilizado como valor de uma propriedade. Um exemplo de expressão CSS:
Além das expressões CSS só funcionarem no Internet Explorer, também há outro problema envolvido: diferentemente do que se possa imaginar, as expressões não são calculadas apenas ao carregar da página ou quando se redimensiona a janela. Elas também são calculadas a cada movimento do mouse sobre a página e quando movemos a barra de rolagem. Se a cada movimento do mouse sobre a tela geramos um cálculo dessa expressão, o movimento horizontal retilíneo de um extremo ao outro de uma página com resolução de 800 x 600 gera 800 cálculos!!!
Se realmente for necessário utilizar expressões CSS, prefira colocar essa expressão no arquivo javascript e setar a propriedade CSS através do Javascript. A vantagem é que você controlará os eventos que manipularão esse cálculo.
Regra 8: Utilize CSS e Javascript em arquivos externos
Em algumas regras anteriores falamos sobre a gerência de arquivos externos pelo HTTP. Aparentemente, há uma recomendação para que os códigos javascript e CSS sejam colocados no mesmo arquivo do código HTML, para diminuir o número de requisições HTTP. Mas não é bem assim!!
Colocar o javascript e CSS em arquivos separados, além de facilitar o reuso e manutenção desses arquivos, possibilitam que o navegador mantenha esses arquivos em cache.
Por outro lado, o javascript e CSS colocados "inline" no HTML não podem ser colocados em cache e têm que ser carregados a cada requisição. Outro fator contrário ao "inline" é que aumentam o tamanho do arquivo HTML e, por conseqüência, o tempo de carregamento desses arquivos.
Por outro lado (quantos lados, hein!), páginas que tem um estilo "único" dentre as outras páginas e normalmente são acessadas apenas uma vez por sessão devem ter seus javascript e CSS "inline", desde que não sejam muito grandes.
Regra 9: Reduza as pesquisas DNS
O DNS mapeia hostnames em endereços IPs para que possam ser feitas as conexões HTTP, assim como uma agenda telefônica mapeia nomes em números telefônicos.
Quando você digita www.tmferreira.com.br/blog/ no seu browser, antes de qualquer coisa, o seu browser solicita ao DNS o IP de www.tmferreira.com.br.
O cache de DNS em sistemas operacionais ou browsers expira rapidamente. Assim, é recomendado que não sejam utilizados muitos hostnames para um website, para que seja reduzido o tempo em pesquisas DNS.
Se você, assim como eu, tem um e-mail do BOL, já deve ter percebido que eles utilizam muitos hostnames. Isso melhora o tempo de carregamento das páginas com os downloads simultâneos, mas aumenta o número de pesquisas DNS.
Essa também é uma das regras que havia mencionado que não se aplicam a grande maioria dos sites, que tem o mesmo hostname para a aplicação toda.
Regra 10: Reduza os Javascripts
Essa regra preconiza que os arquivos javascript em produção devem ser reduzidos. A redução consiste em remover espaços, tabulações, comentários, etc., ou seja, tudo o que não é necessário para o funcionamento do código e que aumentam o tamanho dos arquivos.
Essa técnica é muito utilizada em scripts e frameworks distribuídos na internet. Essas distribuições normalmente são chamadas de packs.
A redução de scripts não tem efeitos colaterais e é indicada sempre que o arquivo já está em produção. Durante o desenvolvimento, a redução dificulta a alteração do código e remoção de bugs.
Regra 11: Evite redirecionamentos
Os redirecionamentos acontecem pelos mais diversos motivos. A aplicação que mais vejo acontece em fóruns. Após você fazer um post, é mostrada uma mensagem (de sucesso ou erro) e depois há o redirecionamento para outra página.
Obviamente que isso deixa aborrecido os usuários que estão acessando de uma conexão lenta.
No iMasters, retiramos o redirecionamento para que a experiência do usuário seja melhor.
Mas há ocasiões em que não dá para escapar do redirecionamento. No meu blog, houve mudança de domínio. Como fazer com que os links do domínio antigo continuassem íntegros? Só com redirecionamento mesmo. Mas há formas e formas de fazer um redirecionamento. A mais rápida e recomendada é diretamente através de um cabeçalho HTTP com resposta 301 ou 302 (no blog foi feito assim). Uma forma de redirecionamento que é mais lenta é através da tag meta refresh.
O importante é ter bom senso e utilizar os redirecionamentos onde é extritamente necessário.
Regra 12: Remova scripts duplicados
Essa regra diz que não devemos fazer inclusões duplicadas (ou triplicadas, ...) de scripts.
Eu não considero isso como uma regra pois não faz o menor sentido em incluir um mesmo script duas ou mais vezes na mesma página. Para mim, isso é um erro e nem precisaria de regra para que os desenvolvedores não o cometam.
Regra 13: Configure ETags
ETags é o acrônimo para Entity Tags. Isto é um mecanismo que servidores WEB e browsers usam para determinar se o arquivo do servidor é o mesmo que está no cache do browser.
O valor da ETag é gerado dependendo das configurações do servidor e de acordo com as características atuais do arquivo.
Essa configuração faz com que o Apache calcule um hash do arquivo baseado na data e hora da sua última modificação. O browser armazena essa ETag em cache. Se eu modificar o arquivo e salvá-lo, a data e hora da última modificação será alterada e, com isso, os valores de ETag entre servidor e browser ficarão diferentes, fazendo com que o arquivo seja recarregado.
A configuração de ETags torna desnecessário o uso de versão no nome dos arquivos de imagens, CSS, Javascript, etc.
Conclusão
Nesse artigo, vimos que o YSlow pode nos dar o caminho das pedras para diminuir o tempo de carregamento das páginas e melhorar a experiência dos visitantes.
Eu não encaro essas regras literalmente. Encaro-as como boas práticas que devem ser seguidas com bom senso e com análise caso a caso. Penso que a nota C é uma ótima nota para a grande maioria dos sites.
Thiago Ferreira
Seu funcionamento é integrado ao plugin FireBug, para o browser Firefox. Portanto, antes de instalar o YSlow no Firefox, é necessário instalar o Firebug.
Este artigo não é uma tradução, mas é baseado nas regras de performance do YSlow, disponíveis da documentação da ferramenta. Além de trechos de adaptados do link original, há opiniões, comentários e conclusões deste que vos "fala".
Mas, por que a performance do front-end é importante?
apenas 5% do tempo de carregamento da página é gasto com o download do código HTML. Os outros 95% são gastos com imagens, CSS, Javascripts, etc..
Uma pesquisa mostrou que 9 dos 10 maiores sites americanos têm, no máximo, 20% do tempo de carregamento gasto com HTML.
Isso nos indica que devemos cuidar da performance do front-end das nossas páginas WEB, a fim de melhorar a experiência do visitante.
As três principais razões para começar pela performance do front-end, segundo os especialistas em performance do Yahoo!:
- Há mais potencial de melhoria de performance no front-end. Melhorar a performance do front-end pela metade reduz em 40% o tempo de resposta, enquanto melhorar pela metade a performance do back-end reduz apenas 10% do tempo de resposta.
- A melhoria de performance através do front-end tipicamente requer menos tempo e recursos do que o back-end.
- É provado que o tuning de performance do front-end funciona! Mais do que 50 equipes do Yahoo! reduziram o tempo de resposta para o usuário em 25% ou mais, seguindo as melhores práticas da equipe de performance do Yahoo!.
Para medir a performance de uma página, o YSlow basea-se em 13 regras. De acordo com a taxa de aderência da página às regras, é dada uma pontuação de A a F para cada regra, onde A representa a nota máxima e F representa a nota mínima. Também é calculada a nota final, com a média das notas obtidas nas 13 regras.
O detalhamento das notas para cada página pode ser vista na aba Performance, do YSlow.
Algumas dessas regras, como veremos a seguir, são proibitivas para a maioria dos sites devido ao custo, complexidade ou freqüência de uso. Vamos às regras!
Regras para Alta Performance
As regras são classificadas de acordo com o seu grau de importância.
Regra 1: Fazer poucas requisições HTTP
Segundo Steve Souders, que é o CARA do time de performance do Yahoo!, 80% do tempo gasto por um usuário numa página é carregando o front-end e que a maior parte desse tempo de carregamento é tomado pelo download de imagens, scripts, css, flash, etc., como já vimos anteriormente.
Então, para melhorar a performance no carregamento da página é importante utilizarmos o menos possível de imagens, css, etc. Para isso, além de otimizar essas requisições fazendo somente as necessárias, pode-se utilizar técnicas citadas por ele:
- Mapa de imagens: quando se tem imagens que podem ser "coladas" umas nas outras, pode-se utilizar mapas de imagens para se detectar onde foi efetuado o clique. Embora o tamanho da imagem unificada seja o mesmo da soma das imagens separadas, o número de requisições diminui. Assim, toda aquela burocracia do HTTP 1.1 para abrir uma conexão e fazer a requisição é diminuída.
- CSS Sprites: podemos utilizar essa técnica quando há substituição de uma imagem por outra, quando passamos o mouse sobre a imagem, por exemplo. As duas imagens são colocadas num mesmo arquivo e, através de CSS só uma delas é mostrada ao usuário. Quando o mouse está sobre a imagem, ela é deslocada, sendo mostrada a parte que estava oculta. Isso dá a impressão que a imagem foi mudada, mas na verdade é a mesma imagem em outra posição.
- Combinar os arquivos de script em um único arquivo. Também podemos fazer isso com arquivos de estilo (CSS). Reduzir o número de requisições HTTP é o principal ponto para melhorar a experiência dos usuários que não estão com os arquivos da sua página em cache.
CDN (Content Delivery Network) pode ser traduzido como "Entregador de Conteúdo na Rede". Embora a (má) tradução tenha dificultado o entendimento, isso é simples de entender. Digamos que você tenha um site de acesso global, como YouTube. Suponha que os arquivos estejam num único servidor aqui no Brasil. Agora imaginem os usuários de outros países e continentes acessando esse conteúdo. O caminho é longo, certo? Caminho longo significa maior tempo para acesso e carga desses arquivos.
O CDN serve justamente para eliminar isso, pois trata-se de uma coleção de servidores de conteúdo distribuídos geográficamente, de forma a minimizar a distância entre o usuário e o conteúdo estático de seu site. O cálculo de proximidade entre usuário e conteúdo é calculado através de saltos (hops) de roteamento ou do tempo de resposta à solicitação.
Mas como eu havia dito antes, há regras do YSlow que são proibitivas pelo custo. Esse é o caso da Regra 2 que, além de ser cara, só é necessário para uma parcela pequena de sites.
Regra 3: Adicione Expires no cabeçalho
O cabeçalho Expires diz ao browser a data que os componentes daquela requisição irão expirar, ou seja, se você determina um prazo de 5 anos para uma página expirar, todos componentes nela contidos somente expirarão em 5 anos. Com isso, todos os componentes (imagens, CSS, scripts, Flash, etc.) serão colocados em cache e, nas próximas visitas, o número de requisições HTTP será menor pois os componentes poderão ser acessados diretamente do cache do browser.
Aí você pergunta: "Mas e se eu fizer uma alteração num componente?". Se você fizer uma alteração, precisará alterar também o nome deste componente. É altamente recomendado que seja acrescentado nos nomes dos componentes informações de versão. Exemplo: estilo_1.css.
Quando você fizer uma alteração neste arquivo, basta alterar a numeração da versão, colocando estilo_2.css.
O uso da linha de código a seguir faz com que os componentes da página que a contém expirar somente em 2012.
[code][/code]
Acontece que o HTTP/1.1 não recomenda o uso de datas de expiração maiores do que um ano. Eu penso que realmente não há necessidade de ser maior do que um ano pois normalmente os caches são limpos pelos usuários com freqüência.
Não recomendo o uso dessa técnica durante o desenvolvimento do projeto pois será mais difícil corrigir bugs e fazer alterações.
Regra 4: Compacte componentes
Esta regra de performance indica que é recomendado que os componentes sejam compactados através da requisição HTTP para que o tempo de resposta seja menor, fazendo com que os componentes sejam carregados mais rapidamente no cliente.
A configuração da forma de compactação e o algoritmo de compactação utilizados variam de acordo com o servidor WEB utilizado.
A compactação é recomendada para qualquer arquivo de texto, como HTML, Javascript, folhas de estilo, XML, JSON, etc. Ela só não é recomendada para alguns tipos de arquivos como imagens e PDF, pois eles já são comprimidos e a compactação seria ineficiente e tomaria recursos do servidor desnecessariamente.
Regra 5: Coloque o CSS no topo
Essa é uma das regras mais simples de seguir. Ela diz que a declaração das folhas de estilo (CSS) deve estar dentro do HEAD do documento. Isso é um tanto quanto óbvio, pois a especificação do HTML já diz isso.
O CSS deve estar no HEAD pois o browser pode renderizar o conteúdo de acordo com a progressão do carregamento dos componentes. Isso trás melhor experiência ao usuário pois ele, além de ver que algo está acontecendo, pode acessar um link que já tenha aparecido no browser antes mesmo da página terminar de carregar.
Quando o CSS não está no HEAD, alguns browsers esperam todo o carregamento da página, para que não tenha que haver reposicionamento ou redesenho de componentes. Enquanto não aparecem, o usuário vê somente uma página em branco. Browsers como o Firefox, que mostram o conteúdo independente do local de declaração do CSS, "correm o risco" de ter que redesenhar ou reposicionar os componentes na tela.
Regra 6: Coloque os scripts embaixo
Os arquivos externos de javascript funcionam da forma contrária aos arquivos CSS, quanto à renderização progressiva. Enquanto o CSS bloqueia a renderização de tudo o que está antes dele até seu carregamento completo, o javascript bloqueia o carregamento de tudo o que está depois dele, até o seu carregamento.
Assim, se você colocar os arquivos de script o mais próximo possível da tag de fechamento do BODY, a renderização de tudo o que está antes do script poderá ser feita independente do carregamento desses arquivos.
Outro fator que justifica a colocação dos scripts tão próximo do fechamento de BODY quanto possível é que os browsers não fazem download de nenhum outro arquivo enquanto fazem o download de um script javascript, independente se é do mesmo servidor ou não.
Eu até achava que os scripts não poderiam ser colocados dentro do BODY, mas, depois que li essa regra, fiz uma pesquisa e constatei que a especificação do HTML não tem nenhuma contra-indicação quanto a isso.
Regra 7: Evite expressões CSS
É possível declarar expressões em CSS através do método expression. Uma expressão CSS utiliza javascript para calcular algum valor que será utilizado como valor de uma propriedade. Um exemplo de expressão CSS:
Além das expressões CSS só funcionarem no Internet Explorer, também há outro problema envolvido: diferentemente do que se possa imaginar, as expressões não são calculadas apenas ao carregar da página ou quando se redimensiona a janela. Elas também são calculadas a cada movimento do mouse sobre a página e quando movemos a barra de rolagem. Se a cada movimento do mouse sobre a tela geramos um cálculo dessa expressão, o movimento horizontal retilíneo de um extremo ao outro de uma página com resolução de 800 x 600 gera 800 cálculos!!!
Se realmente for necessário utilizar expressões CSS, prefira colocar essa expressão no arquivo javascript e setar a propriedade CSS através do Javascript. A vantagem é que você controlará os eventos que manipularão esse cálculo.
Regra 8: Utilize CSS e Javascript em arquivos externos
Em algumas regras anteriores falamos sobre a gerência de arquivos externos pelo HTTP. Aparentemente, há uma recomendação para que os códigos javascript e CSS sejam colocados no mesmo arquivo do código HTML, para diminuir o número de requisições HTTP. Mas não é bem assim!!
Colocar o javascript e CSS em arquivos separados, além de facilitar o reuso e manutenção desses arquivos, possibilitam que o navegador mantenha esses arquivos em cache.
Por outro lado, o javascript e CSS colocados "inline" no HTML não podem ser colocados em cache e têm que ser carregados a cada requisição. Outro fator contrário ao "inline" é que aumentam o tamanho do arquivo HTML e, por conseqüência, o tempo de carregamento desses arquivos.
Por outro lado (quantos lados, hein!), páginas que tem um estilo "único" dentre as outras páginas e normalmente são acessadas apenas uma vez por sessão devem ter seus javascript e CSS "inline", desde que não sejam muito grandes.
Regra 9: Reduza as pesquisas DNS
O DNS mapeia hostnames em endereços IPs para que possam ser feitas as conexões HTTP, assim como uma agenda telefônica mapeia nomes em números telefônicos.
Quando você digita www.tmferreira.com.br/blog/ no seu browser, antes de qualquer coisa, o seu browser solicita ao DNS o IP de www.tmferreira.com.br.
O cache de DNS em sistemas operacionais ou browsers expira rapidamente. Assim, é recomendado que não sejam utilizados muitos hostnames para um website, para que seja reduzido o tempo em pesquisas DNS.
Se você, assim como eu, tem um e-mail do BOL, já deve ter percebido que eles utilizam muitos hostnames. Isso melhora o tempo de carregamento das páginas com os downloads simultâneos, mas aumenta o número de pesquisas DNS.
Essa também é uma das regras que havia mencionado que não se aplicam a grande maioria dos sites, que tem o mesmo hostname para a aplicação toda.
Regra 10: Reduza os Javascripts
Essa regra preconiza que os arquivos javascript em produção devem ser reduzidos. A redução consiste em remover espaços, tabulações, comentários, etc., ou seja, tudo o que não é necessário para o funcionamento do código e que aumentam o tamanho dos arquivos.
Essa técnica é muito utilizada em scripts e frameworks distribuídos na internet. Essas distribuições normalmente são chamadas de packs.
A redução de scripts não tem efeitos colaterais e é indicada sempre que o arquivo já está em produção. Durante o desenvolvimento, a redução dificulta a alteração do código e remoção de bugs.
Regra 11: Evite redirecionamentos
Os redirecionamentos acontecem pelos mais diversos motivos. A aplicação que mais vejo acontece em fóruns. Após você fazer um post, é mostrada uma mensagem (de sucesso ou erro) e depois há o redirecionamento para outra página.
Obviamente que isso deixa aborrecido os usuários que estão acessando de uma conexão lenta.
No iMasters, retiramos o redirecionamento para que a experiência do usuário seja melhor.
Mas há ocasiões em que não dá para escapar do redirecionamento. No meu blog, houve mudança de domínio. Como fazer com que os links do domínio antigo continuassem íntegros? Só com redirecionamento mesmo. Mas há formas e formas de fazer um redirecionamento. A mais rápida e recomendada é diretamente através de um cabeçalho HTTP com resposta 301 ou 302 (no blog foi feito assim). Uma forma de redirecionamento que é mais lenta é através da tag meta refresh.
O importante é ter bom senso e utilizar os redirecionamentos onde é extritamente necessário.
Regra 12: Remova scripts duplicados
Essa regra diz que não devemos fazer inclusões duplicadas (ou triplicadas, ...) de scripts.
Eu não considero isso como uma regra pois não faz o menor sentido em incluir um mesmo script duas ou mais vezes na mesma página. Para mim, isso é um erro e nem precisaria de regra para que os desenvolvedores não o cometam.
Regra 13: Configure ETags
ETags é o acrônimo para Entity Tags. Isto é um mecanismo que servidores WEB e browsers usam para determinar se o arquivo do servidor é o mesmo que está no cache do browser.
O valor da ETag é gerado dependendo das configurações do servidor e de acordo com as características atuais do arquivo.
Essa configuração faz com que o Apache calcule um hash do arquivo baseado na data e hora da sua última modificação. O browser armazena essa ETag em cache. Se eu modificar o arquivo e salvá-lo, a data e hora da última modificação será alterada e, com isso, os valores de ETag entre servidor e browser ficarão diferentes, fazendo com que o arquivo seja recarregado.
A configuração de ETags torna desnecessário o uso de versão no nome dos arquivos de imagens, CSS, Javascript, etc.
Conclusão
Nesse artigo, vimos que o YSlow pode nos dar o caminho das pedras para diminuir o tempo de carregamento das páginas e melhorar a experiência dos visitantes.
Eu não encaro essas regras literalmente. Encaro-as como boas práticas que devem ser seguidas com bom senso e com análise caso a caso. Penso que a nota C é uma ótima nota para a grande maioria dos sites.
Thiago Ferreira
Assinar:
Postagens (Atom)
